
🔥Building a Slack Bot with AI Capabilities - Part 6, adding support for DOC/X, XLS/X, PDF, and More to Chat with your Data🔥
aka, please don't make me create a pivot table, I'd rather just ask you

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
These articles are supported by readers, please consider subscribing to support me writing more of these articles <3 :)
This article is part of a series of articles, because 1 article would be absolutely massive.
Part 1: Covers how to build a slack bot in websocket mode and connect to it with python
Part 4: How to convert your local script to an event-driven serverless, cloud-based app in AWS Lambda
Part 6 (this article): Switching to the .converse() API to support DOC/DOCX, XLS/XLSX, PDF, and others to chat with your data
Part 7: Streaming token responses from AWS Bedrock to your AI Slack bot using converse_stream()
Part 8: ReRanking knowledge base responses to improve AI model response efficacy
Part 9: Adding a Lambda Receiver tier to reduce cost and improve Slack response time
Hey all!
So far we’ve built a functional chatbot using AWS Lambda and Bedrock, and had it read our entire confluence so it can talk to us about it. That’s so cool!
But on the user-facing side, we can only talk to it via image or text. We did include Slack “snippets”, which are sort of like code blocks, but what if I want the AI to:
Read a PDF contract of mine to summarize what I’m agreeing to?
Look at the sales data spreadsheet from the past quarter and identify if there’s any clients that aren’t spending quite as much as last quarter?
Read my project proposal document and give me some tips?
Read the resume of an upcoming interviewee and let me know some questions to test their knowledge level versus a job description?
The bot doesn’t yet have the ability to read documents, but as you can probably guess from this article’s title and my build-up, we’re going to teach it!!
Here’s an example of analyzing a resume:
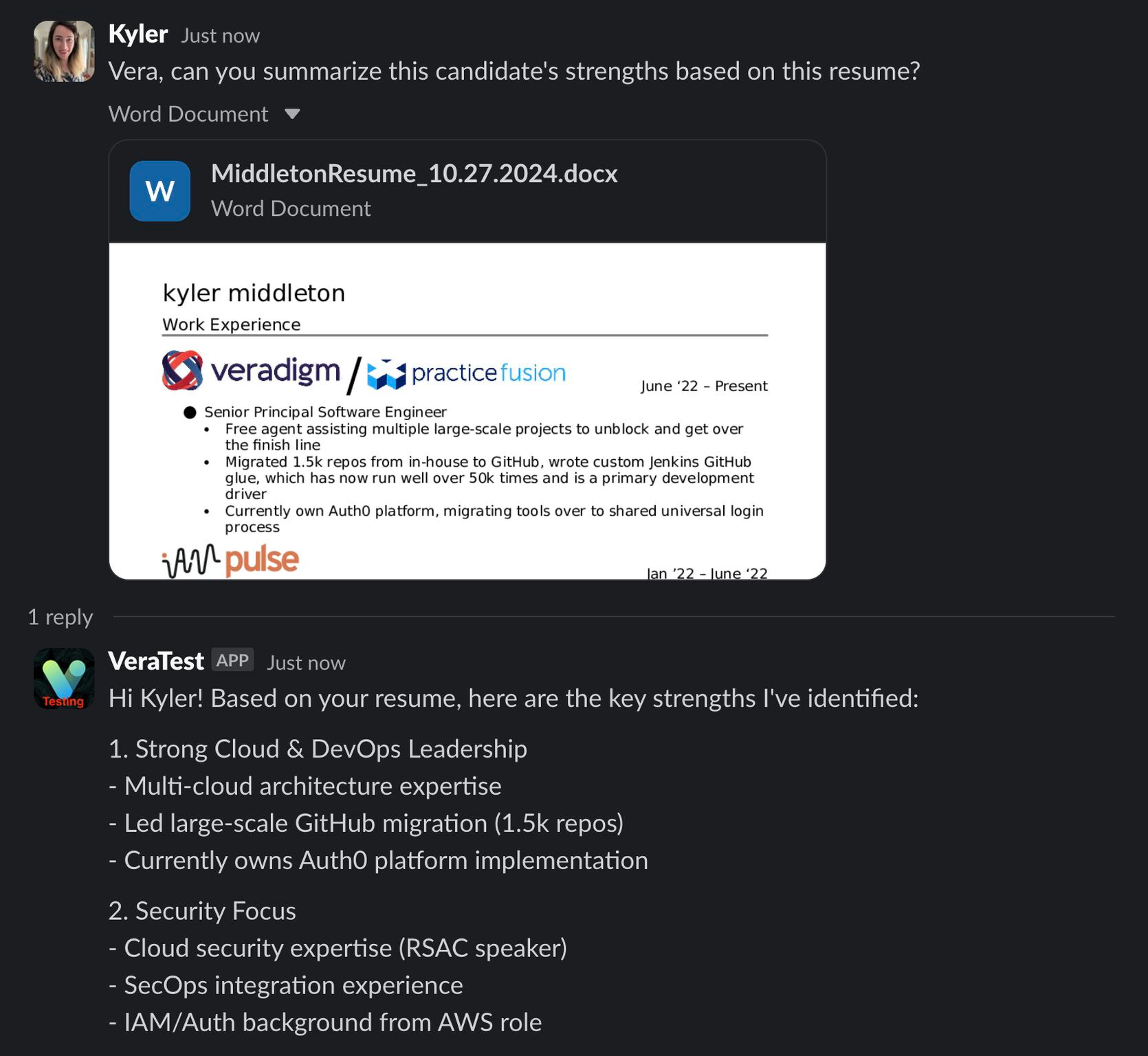
Since we can have long conversations with Vera, we can give her a job description and also a candidate resume and get feedback on what we should ask the candidate to talk about their perceived gaps.

Vera can also analyze contracts and explain what you’re agreeing to, which is a really useful talent, particularly for private AI use cases.
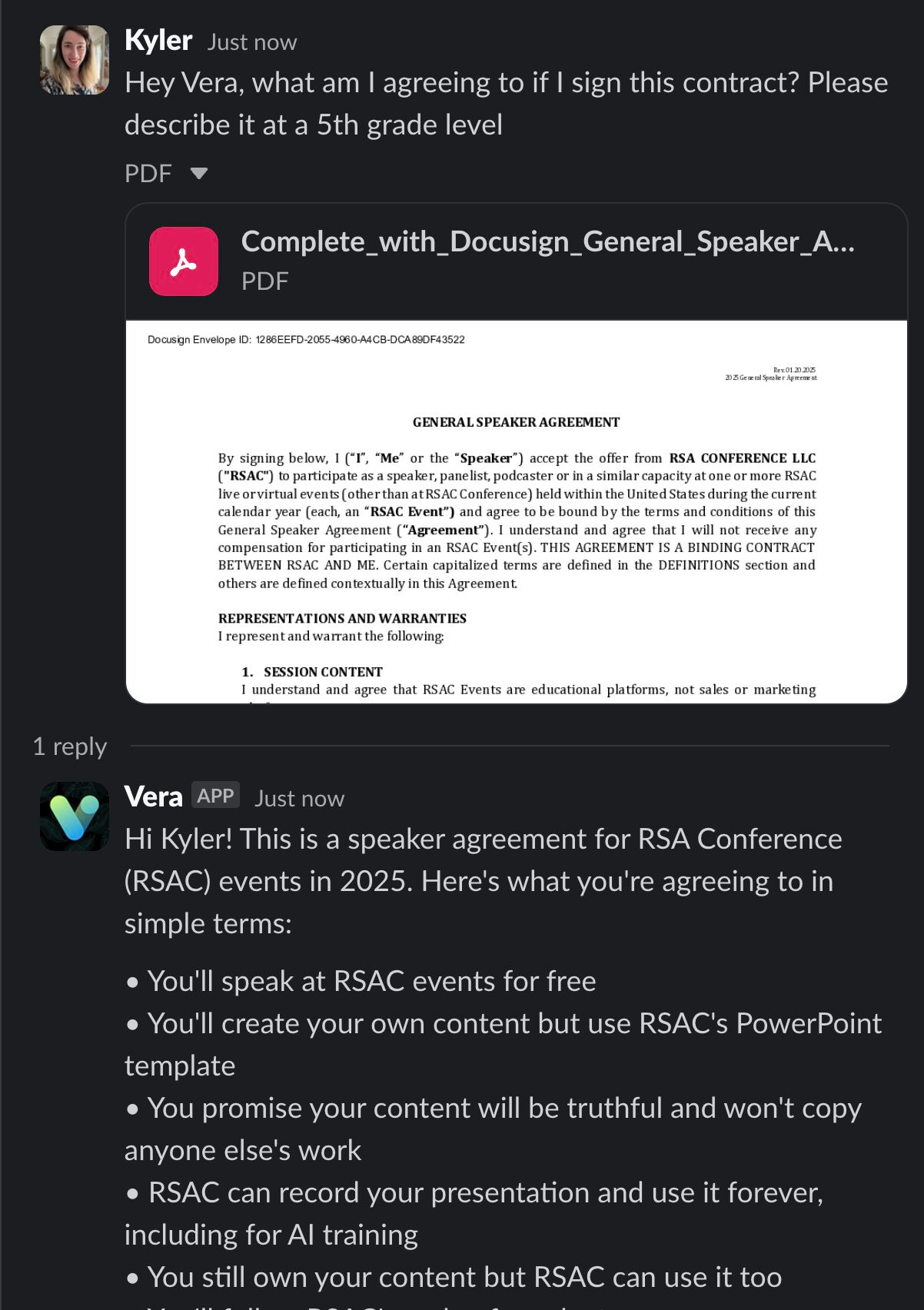
With no further ado, lets do it!!
If you’d rather skip all this walk-through and read the code yourself, the repo at github/kymidd/SlackAIBotServerless is public and MIT licensed for free use ;)
The .Converse() API
Models can be called directly via Bedrock using the .invoke_model() API. This API directly forwards your payload to the model. This has some great benefits like supporting any cool bespoke thing the model can do, but it has some draw-backs too - each model’s API is a bit different, so if you want to steer your questions to different models, or might one-day switch, it can be a pain to do so.
To combat this, AWS decided to build something better - they built a meta-API called .Converse(). This is an API endpoint that goes directly to Bedrock, and they receive your requests using a standard API structure, and format it for whatever model you’re forwarding to, and then they facilitate the connection through.
That is really powerful in terms of standardization, but we’re looking at it for an entirely different reason.
The .converse() API has support for document reads that Claude Sonnet directly doesn’t!
How does it do that? I have absolutely no idea. But I know that it does, which is super rad.
How Do We .Converse?
There are no permissions changes, since the .invoke() and .converse() APIs use the same IAM permissions - bedrock:InvokeModel.
So we can jump right to code. Lets update our previous code to support this new API.
First step, we need to define a top_k, which we didn’t need to do before.
Top-K limits the next word choices to `n` options (like the next most likely 25, in this example), vs temperature, which is the randomization for which it picks the next token/word.
This is a global setting we’ll define right at the top in globals, right here.
| top_k = 25 |
The .converse() API uses a standardized format for conversations, which is similar to what the Claude Sonnet model uses in the previously implemented .invoke() implementation, but not quite.
The previous one looks like this:
| response = bedrock_client.invoke_model( | |
| modelId=model_id, | |
| guardrailIdentifier=guardrailIdentifier, | |
| guardrailVersion=guardrailVersion, | |
| body=json.dumps( | |
| { | |
| "anthropic_version": anthropic_version, | |
| "max_tokens": 1024, | |
| "messages": messages, | |
| "temperature": temperature, | |
| "system": model_guidance, | |
| } | |
| ), | |
| ) |
And the new .converse() call looks like this:
| response = bedrock_client.converse( | |
| modelId=model_id, | |
| guardrailConfig={ | |
| "guardrailIdentifier": guardrailIdentifier, | |
| "guardrailVersion": guardrailVersion, | |
| }, | |
| messages=messages, | |
| system=model_prompt, | |
| inferenceConfig=inference_config, | |
| additionalModelRequestFields=additional_model_fields | |
| ) |
We have to prep a few things to support this conversation ^^, namely:
line 2 - the model prompt. This is the “system prompt” or “system instructions”, which (heavily) guide how the model behaves. We don’t pass it directly as a heredoc string like before, instead we pass it as a conversation-turn-esque structure, so we construct that here.
line 9 - we create the “inference_config” block, which right now just contains the temperature configuration.
On line 14, we create the additional info, the top_k, to pass to the model.
additional_model_fields is the structure that’s passed directly to the model, and isn’t used by the .converse() API directly.
| # Format model system prompt for the request | |
| model_prompt = [ | |
| { | |
| "text": model_guidance | |
| } | |
| ] | |
| # Base inference parameters to use. | |
| inference_config = { | |
| "temperature": temperature | |
| } | |
| # Additional inference parameters to use. | |
| additional_model_fields = { | |
| "top_k": top_k | |
| } |
We also add some error handling around the request handler. Instead of just doing the request, and writing the fail to the CloudWatch logs, instead we catch the error and return it as the “response”. That means that if there is any failure in the request, we send the failure back to the user.
That is extra helpful here, with supporting documents, because not all document types are supported, and all are limited to a particular size, and among 5-10 files of any type are supported in a conversation, etc.
Writing all that error handling myself is bound to be complex and failure-prone, and even if I get it perfect those limitations might change in the future as the model and .converse() improves.
Easiest solution here is to just rely on the .converse() API to do its own error handling, and if it throws an error (like “too many files attached”), and return it to the user since they might be able to change something (like delete an attached file) themselves, without involving me (or you!) to find the error or try and resolve it for them.
| # Try to make the request | |
| try: | |
| response = bedrock_client.converse( | |
| # ... excluded call | |
| ) | |
| # Find the response text | |
| response = response["output"]["message"]["content"][0]["text"] | |
| except Exception as error: | |
| # If the request fails, print the error | |
| print(f"🚀 Error making request to Bedrock: {error}") | |
| # Clean up error message, grab everything after the first : | |
| error = str(error).split(":", 1)[1] | |
| # Return error as response | |
| response = "😔 Error with request: " + str(error) |
Support Attaching Files
Okay, next up, attaching files. We’ve previously implemented attaching files, but were pretty limited - we were only able to attach a few types of images. But now the world is opened up, and we can attach way more!
So lets go revisit that logic. We have a function called build_conversation_content() function that we call for each slack message in the thread as we iterate over the message. We check for the user’s information, if there is any text in the message (unintuitively, slack doesn’t require a text message to be attached for every document file, you can send a document without any text), and also if there’s any files referenced from the message.
Note I said “referenced”, not attached. Neither the webhook nor the thread message history contains the actual binary of the files attached, just URLs where we can go get them, so we have to crawl over the list of every file attached to every message in the entire thread, find their download URLs, download them, and attach them in the right format. It’s a lot! Let’s walk through how.
Lets start in the build_conversation_content() function. We’re handed off a single “message” payload, and we can read it to see if there is a key called “files”. If not, we skip all this logic and just move on - it’s probably just a text message.
On line 4, we start iterating over the files in the payload, since Slack permits us to attach A LOT of files.
On line 11, we look up the name of the file, and remove anything before the `.` period character that probably falls right before the file extension. Regardless, we’re not permitted to include periods in the file name, so we remove it and just identify the file name that comes before the period.
Weird/fun fact: The Bedrock API requires a file name for each file, and doesn’t permit the file to be attached twice in a single conversation. No clue why.
Next on line 14, we find the “private url download” link that’s an http web address, and save it.
On line 17, we go get the object using a bearer token that the app uses to authenticate. This stores the binary copy of the file in memory as the “file_object”.
On line 22 we extract the binary bytes of the file as file_content from the file_object blob.
| # If the payload contains files, iterate through them | |
| if "files" in payload: | |
| # Append the payload files to the content array | |
| for file in payload["files"]: | |
| # Debug | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 File found in payload:", file) | |
| # Isolate name of the file and remove characters before the final period | |
| file_name = file["name"].split(".")[0] | |
| # File is a supported type | |
| file_url = file["url_private_download"] | |
| # Fetch the file and continue | |
| file_object = requests.get( | |
| file_url, headers={"Authorization": "Bearer " + token} | |
| ) | |
| # Decode object into binary file | |
| file_content = file_object.content |
Next, we check the file’s “mimetype”. That’s a header value sometimes called a “magic byte” that identifies the structure of the file. We use that to check which path we should go down to encode the file.
For images there’s a different way to encode the file for the bedrock conversation than for document type files, so we separate the logic.
On line 10, we identify the file type by reading the mimetype and then saving only everything after the forward slash. So “image/png” becomes “png”.
Slack stores types of files as “image/png”, and bedrock expects “png”, that’s why we do this.
Then on line 13 we append the image to the content block that we’re building.
Note on line 18 we’re literally appending the bytes to the message. We’re not base64 encoding it or otherwise packaging it up. Literally copy paste into the payload. Cool.
| # Check the mime type of the file is a supported image file type | |
| if file["mimetype"] in [ | |
| "image/png", # png | |
| "image/jpeg", # jpeg | |
| "image/gif", # gif | |
| "image/webp", # webp | |
| ]: | |
| # Isolate the file type based on the mimetype | |
| file_type = file["mimetype"].split("/")[1] | |
| # Append the file to the content array | |
| content.append( | |
| { | |
| "image": { | |
| "format": file_type, | |
| "source": { | |
| "bytes": file_content, | |
| } | |
| } | |
| } | |
| ) |
Then we do the whole thing again, except this time we’re checking if the mimetype of the file is one of the sweet new document types that we support. You’ll see PDFs (line 3), CSV (line 4), word docs (line 5, 6), excel (line 7, 8), html and markdown (line 9, 10).
If it is, we read through the mimetype list and write down the type of file. Most of them follow the same type of “strip off the application/” to get the type, but not all - check out “application/msword” mimetype is actually file type “docx” and “application/vnd.ms-excel” is actually “xlsx”.
| # Check if file is a supported document type | |
| elif file["mimetype"] in [ | |
| "application/pdf", | |
| "application/csv", | |
| "application/msword", | |
| "application/vnd.openxmlformats-officedocument.wordprocessingml.document", | |
| "application/vnd.ms-excel", | |
| "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet", | |
| "text/html", | |
| "text/markdown", | |
| ]: | |
| # Isolate the file type based on the mimetype | |
| if file["mimetype"] in ["application/pdf"]: | |
| file_type = "pdf" | |
| elif file["mimetype"] in ["application/csv"]: | |
| file_type = "csv" | |
| elif file["mimetype"] in ["application/msword", "application/vnd.openxmlformats-officedocument.wordprocessingml.document"]: | |
| file_type = "docx" | |
| elif file["mimetype"] in ["application/vnd.ms-excel", "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"]: | |
| file_type = "xlsx" | |
| elif file["mimetype"] in ["text/html"]: | |
| file_type = "html" | |
| elif file["mimetype"] in ["text/markdown"]: | |
| file_type = "markdown" |
Then on line 2, we similarly append the file.
On line 15, we append something again. That’s weird, right? The Bedrock API requires a description of the file. Slack doesn’t always provide one, so what do we do?
Well, I made the super duper clever choice to add a hard-coded text message of “file” to the conversation whenever a document is attached.
You can see on line 17 I played with adding other smart stuff to the thread, but I’m too worried about muddying the waters for what bedrock should be doing - answering our questions about the document, instead of describing the description we’re providing.
If anyone has a clever way to actually do something with this field, curious what you do there.
| # Append the file to the content array | |
| content.append( | |
| { | |
| "document": { | |
| "format": file_type, | |
| "name": file_name, | |
| "source": { | |
| "bytes": file_content, | |
| } | |
| } | |
| } | |
| ) | |
| # Append the required text to the content array | |
| content.append( | |
| { | |
| #"text": "This file is named " + file_name + " and is a " + file_type + " document.", | |
| "text": "file", | |
| } | |
| ) |
Summary
And that’s pretty much it! This took a great deal of trial and error, but in the end only took about 90 minutes to switch from the direct model.invoke() method to the converse() method.
Here’s the PR where I implemented it on the public codebase - it’s MIT licensed, go use it! It’s free.
Next up, we’ll be streaming tokens back to slack, and adding some immediate feedback to the user that we’re on it. We can even tell some jokes while they’re waiting.
Thanks all folks. Good luck out there.
kyler