
🔥Building a Slack Bot with AI Capabilities - Part 7, Streaming Token Responses from AWS Bedrock to Slack using converse_stream()🔥
aka: AI, what are you doing while I wait? ⏳

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
These articles are supported by readers, please consider subscribing to support me writing more of these articles <3 :)
This article is part of a series of articles, because 1 article would be absolutely massive.
Part 1: Covers how to build a slack bot in websocket mode and connect to it with python
Part 4: How to convert your local script to an event-driven serverless, cloud-based app in AWS Lambda
Part 7 (this article!): Streaming token responses from AWS Bedrock to your AI Slack bot using converse_stream()
Part 8: ReRanking knowledge base responses to improve AI model response efficacy
Part 9: Adding a Lambda Receiver tier to reduce cost and improve Slack response time
Hey all!
So far in this series we’ve created a slack bot, connected it to a python-based Lambda, and taught that lambda to walk a whole slack conversation to build a conversation. That conversation is flattened and sent to the knowledge base to get some relevant context from Confluence, and the responses are added as conversation turns. The whole conversation payload is sent to Bedrock to get a response, and then that response is returned to the user in slack as a post.
That’s a ton of things, and sometimes it takes a little bit (5-10 seconds) for that all to happen. In the mean-time, the user is waiting in slack, sure hoping that the bot will eventually respond.
Wouldn’t it be cooler if the bot immediately responded that it got the message, and kept you updated as it cycled through the stages of what it was doing? And then we could even have it stream the tokens from the AI in case you get a long response.
Here’s what it looks like:
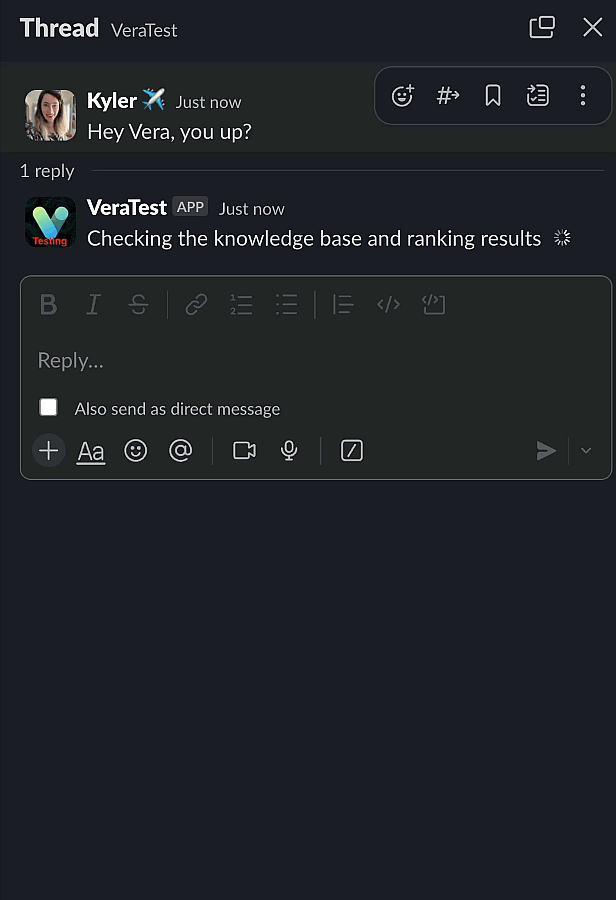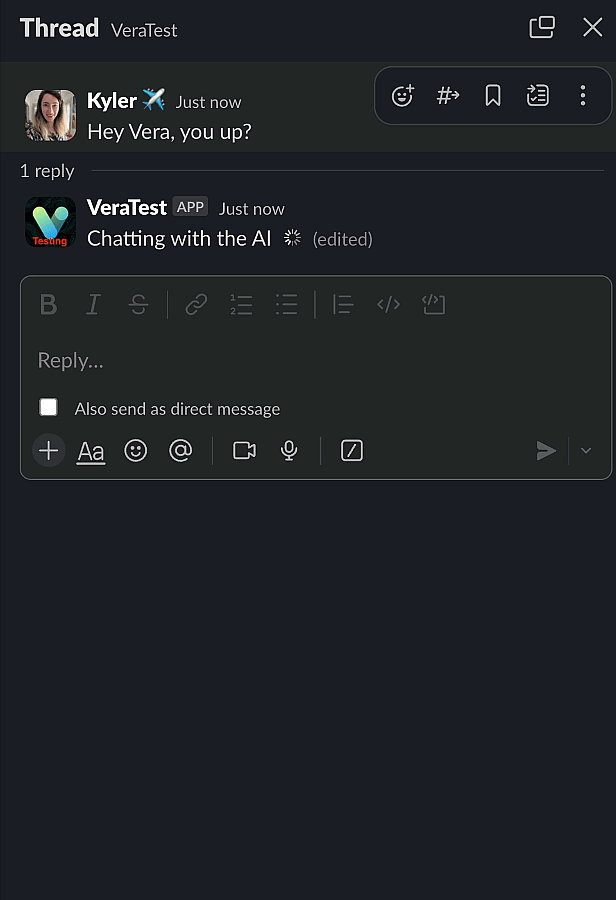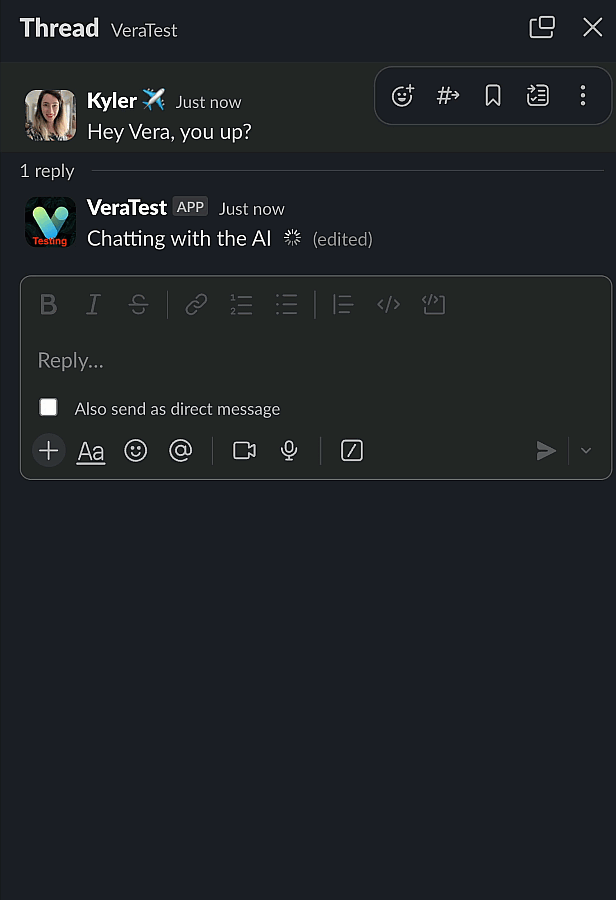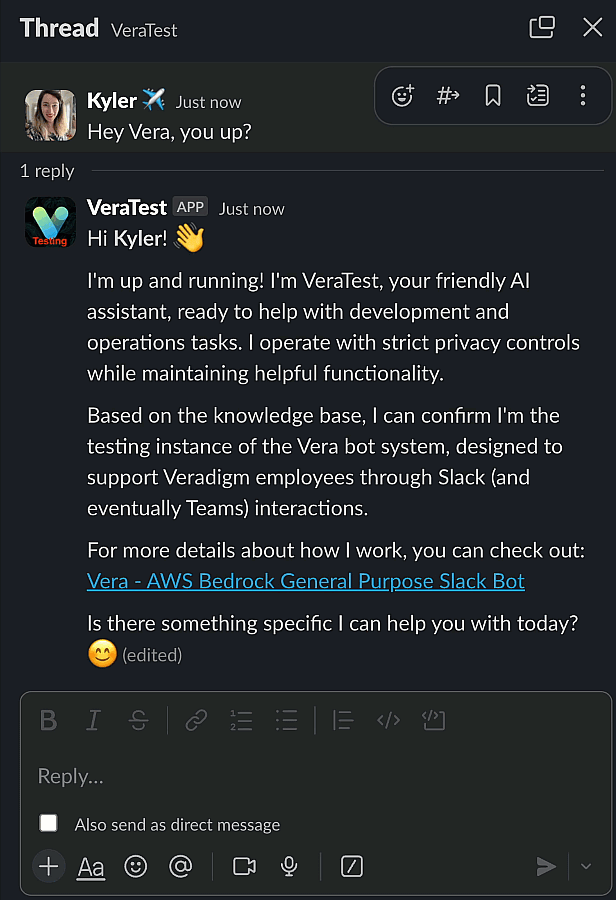
When you’re streaming a longer response, the effect is even more pronounced. When we’re not streaming, our Lambda will wait until the AI entirely finishes building the response. The entire time we’re seeing updates flow to the screen would just be a blank, no response time.
I build this for a very simple reason - on complicated questions, I kept thinking that the AI had broken. When it’s streaming the response, I know it’s working through things.
This feature is already implemented in the code-base, and all code is MIT open source so you can implement it yourself, code is here:
With no further ado, lets walk through it.
Slack Message Editing
The way the slack app guidelines advise you to post as a bot is to use the say() action, which is part of the Slack Bolt framework, and works exactly as expected. However, there are a few parts of say() that we need to understand to work with it properly.
First of all, say() posts outside of a slack thread - it responds to the user as a top-level message.
| say( | |
| text=message_text, | |
| ) |
However, this is easy to customize, you can add a “thread_ts”, a thread time-stamp, which is used as a GUID to identify a particular thread to post to. That means it’ll respond in a thread, woot!
| say( | |
| text=message_text, | |
| thread_ts=thread_ts, | |
| ) |
There’s another limitation we need to be aware of - say() doesn’t support editing a message. So for any type of revolving “status” message for what stage we’re in, or “streaming” (via editing a single message), we can’t use say(). Instead we’ll use client.chat_update(). To make that work, we need to pass in:
text - the contents of the text message to update it to. Notably, this isn’t an “append” method, but a “replace” method
channel - The ID of the channel to search for a message timestamp in (they are only guaranteed unique GUIDs within a single slack room)
ts - the time-stamp of the message to update. Again, time-stamps in slack are used as GUIDs
| client.chat_update( | |
| text=message_text, | |
| channel=channel_id, | |
| ts=message_ts, | |
| ) |
Is this the first message or…
The complicated part of this is that the first post should use say(), and we should capture the time-stamp of the message, which is returned from the say() invocation (yay!), but on any further status messages, we should use a different function.
When I first started building this logic, it was easy to keep straight - step 1, status message, step 2, over-write with AI conversation. However, as this logic has gotten more complex, and I added feature flags for knowledge base(s), re-ranking, pre-staging AI steps, it’s getting harder and harder to keep track of what the first message is vs any downstream ones.
So I set out to build an idempotent method for posting/updating a message.
First in the main message handler function, which is called immediately from the main function after initialization, we initialize the message_ts with a value - None.
This is required because we’ll be sending the message_ts with every call of the “update the status message” regardless of whether we’ve called it before, meaning function default values wouldn’t help, and we can’t handle this logic within the function. So we need it to be set to something, so we set as None to start.
| # Common function to handle both DMs and app mentions | |
| def handle_message_event(client, body, say, bedrock_client, app, token, registered_bot_id): | |
| # Initialize message_ts as None | |
| # This is used to track the slack message timestamp for updating the message | |
| message_ts = None |
Here’s the function I wrote. We receive all the stuff we require to post either a first message or an update, and notably we receive the message_ts which MIGHT have value of None, or might have a real timestamp value.
On line 5, we immediately check if message_ts is set yet. If it’s still None, it means we haven’t yet posted anything as a response. That means we follow the “new post” logic. We store the response as slack_response, and extract the message_ts (timestamp) as message_ts.
If message_ts is any value other than None, we’ve previously responded in slack, and we need to update that message instead, line 14. In this branch of logic we don’t need to store any value, since message_ts is already known.
On line 21, we pass the value of message_ts back. It’s either set to the new message_ts value from a first posting or remains the exact same unmodified value if we’ve previously posted a message and we just edited it, flowing right through the function call unmodified.
| # Update slack response - handle initial post and streaming response | |
| def update_slack_response(say, client, message_ts, channel_id, thread_ts, message_text): | |
| # If message_ts is None, we're posting a new message | |
| if message_ts is None: | |
| slack_response = say( | |
| text=message_text, | |
| thread_ts=thread_ts, | |
| ) | |
| # Set message_ts | |
| message_ts = slack_response['ts'] | |
| else: | |
| # We're updating an existing message | |
| client.chat_update( | |
| text=message_text, | |
| channel=channel_id, | |
| ts=message_ts, | |
| ) | |
| # Return the message_ts | |
| return message_ts |
asdf
And here’s how we’d call it. We set message_ts (remember, this function will either send back the same message_ts or set a new one, so we have to capture it to account for all outcomes) with all the necessary references (say(), client, channel_id, etc.), as well as the message text we want to use as an update.
Here we have a sad face with an error (because errors are sad).
| message_ts = update_slack_response( | |
| say, client, message_ts, channel_id, thread_ts, | |
| f"😔 Error with request: " + str(error), | |
| ) |
And that’s how we’re sending status messages to slack! I’ve been testing it, and this pattern works really well and I don’t have to know if this is the first message or not, which changes depending on which feature flags are enabled at some points.
But what about when we’re streaming the super long responses back from the model? Lets go look.
Streaming Tokens from Bedrock to Slack with Converse_Stream()
In previous articles in this series, we were making a final request to the AI after optionally fetching content from the knowledge base, and then also optionally re-ranking those results (which will be covered in the next article in this series).
We were using the converse() API endpoints, which works great (I sincerely love it), but it means that we wait for the AI to entirely finish the response before we send anything back to Slack. That might mean we’re waiting for a long time for it to finish, particularly for complicated requests.
Much better would be the ChatGPT-esque streaming tokens, where the model starts responding almost immediately as it comes up with tokens.
Lets switch over to the converse_stream model.
Here’s what we were doing before - we’d use the converse() method (the monolithic, blocking way) and we’d extract the entire response and send it back on line 13.
| response = bedrock_client.converse( | |
| modelId=model_id, | |
| guardrailConfig={ | |
| "guardrailIdentifier": guardrailIdentifier, | |
| "guardrailVersion": guardrailVersion, | |
| }, | |
| messages=messages, | |
| system=model_prompt, | |
| inferenceConfig=inference_config, | |
| additionalModelRequestFields=additional_model_fields | |
| ) | |
| # Find the response text | |
| response = response["output"]["message"]["content"][0]["text"] |
Updating to using the streaming method is SUPER EASY, you update bedrock_client.converse() to bedrock_client.converse_stream(). The arguments stay exactly the same. It’s awesome.
However, now that we’re processing token chunks, rather than a single text block, the logic to read and relay those chunks is more complex. Lets call a function we’ll write next instead.
| streaming_response = bedrock_client.converse_stream( | |
| # Same stuff as in converse() | |
| ) | |
| # Call function to respond on slack | |
| response_on_slack(client, streaming_response, message_ts, channel_id, thread_ts) |
Here’s part 1 of the function. We receive all the same information on line 1, and check for debugging on line 4. These are littered all over the code to help me diagnose stuff. One day I’ll embrace break points, for today I print stuff out a lot :D
On line 8-10, we establish a few tracking variables. There’s almost no code but it’s important to understand why these exist.
response - This is a string variable to hold the whole response. As we iterate over tokens, we’ll append them to this variable and then update the slack response with the product.
If we just update slack with the token string literal, it’d only contain the most recent token, instead of the whole response with the new tokens streaming as edits.
token_counter - I initially edited the slack message for every token. It looks SO COOL to see individual words/tokens stream to slack. I also immediately hit an API limit for editing per minute. Instead, we count every token so we can take an action (update slack’s response) every xx tokens. I’m using every 10 tokens for a start, it avoids API rate limits so far.
Slack’s message edit function for Apps permits ~50 edits per minute across any conversation. If you’re streaming individual tokens you’ll hit it right away. We use a higher token slush bucket of 10, which seems to work well for now. If your app is widely adopted, you might have to bump this up to avoid the (globally-measured) rate limit in your slack.
buffer - Every time we read a chunk, we store the text content in the buffer. We build up the buffer, and every 10 tokens, we dump it to slack. If we don’t hit the 10 counter (which will almost always happen on the final bit of the response), the buffer still contains some token string, and we dump that to slack to finish out the operation.
| def response_on_slack(client, streaming_response, message_ts, channel_id, thread_ts): | |
| # Print streaming response | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 Streaming response:", streaming_response["stream"]) | |
| # Counter and buffer vars for streaming response | |
| response = "" | |
| token_counter = 0 | |
| buffer = "" |
Here’s the next part of our streaming, where we use those vars. We iterate over the response stream and read the chunks. We extract the text from every chunk (line 4) and append it both to the response and buffer (line 5, 6). We also increment the token counter, line 7.
On line 9, we check if the token counter is 10. If it is, we update the slack chat, line 10.
Then we zero out the token counter (line 16) since we dumped our buffer (which we also zero out, line 17) to slack.
| # Iterate over streamed chunks | |
| for chunk in streaming_response["stream"]: | |
| if "contentBlockDelta" in chunk: | |
| text = chunk["contentBlockDelta"]["delta"]["text"] | |
| response += text | |
| buffer += text | |
| token_counter += 1 | |
| if token_counter >= 10: | |
| client.chat_update( | |
| text=response, | |
| channel=channel_id, | |
| ts=message_ts | |
| ) | |
| # Every time we update to slack, we zero out the token counter and buffer | |
| token_counter = 0 | |
| buffer = "" |
Finally, we check if the buffer contains anything. If not, we hit exactly at a “divisible by 10” chunk, which happens. If not, there’s a bit of messages stashed in our buffer that aren’t sent to slack yet, so we update the chat one final time with the last bit of the slush bucket buffer.
| # If buffer contains anything after iterating over any chunks, add it also | |
| # This completes the update | |
| if buffer: | |
| client.chat_update( | |
| text=response, | |
| channel=channel_id, | |
| ts=message_ts | |
| ) |
Summary
And that’s pretty much it! We walked through the human benefit of having immediate status messages show up in slack, and then implemented a super simple (and I think clever!) function to handle that idempotently so we can stop worrying about logic streams and go on with our lives.
We also walked through the different methodology we can use for the converse() API, and how easy it is to enable streaming.
All code is MIT open sourced, so GO BUILD THIS it’s so cool, cheap, flexible, and great for your resume.
Good luck out there! Next up - re-ranking responses from the knowledge base.
kyler