


🔥Building Better GenAI: Pre-Contextualizing Knowledge Base Results🔥
aka, the knowledge base would really like to know this

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
I’m calling my “Building a Slack Bot with AI Capabilities” series done, but I’m not done improving and building GenAI tools. This article will continue building the maturity of GenAI by establishing patterns that make these tools more powerful.
When you ask Vera, the bot we’ve built over the past 9 entries into the Building… series, a question, a LOT of stuff happens in the background. It’s mostly invisible to you, but it:
Walks the Slack thread to construct a bedrock-compatible conversation
Flattens the conversation to a string-ified convo, then queries the Bedrock Knowledge Base (which is really OpenSearch in a trenchcoat) for 25-50 relevant vectorized results
Use the reranker() model to match results to your question to improve the fidelity of results
Query the actual model for an answer, including all the compiled context
And it generally does a very good job, particularly for “chat with the knowledge base” style queries. However, that’s not always what we want. Sometimes we have highly structured data and we want to standardize or shim in other contextual data derived from what the user has entered before we query the knowledge base.
I’ve been playing around with adding an additional step, highlighted in the picture below, that derives structured data to assist the knowledge base in obtaining better results, from the unstructured information the user provides. It changes the pattern to look like this, bolded step is the new one:
Walks the Slack thread to construct a bedrock-compatible conversation
Query a model with instructions on how to standardize the data and what keywords would be needed to return high quality info. Ephemerally store that answer and provide to the knowledge base dip.
Flattens the conversation to a string-ified convo, then queries the Bedrock Knowledge Base (which is really OpenSearch in a trenchcoat) for 25-50 relevant vectorized results
Use the reranker() model to match results to your question to improve the fidelity of results
Query the actual model for an answer, including all the compiled context
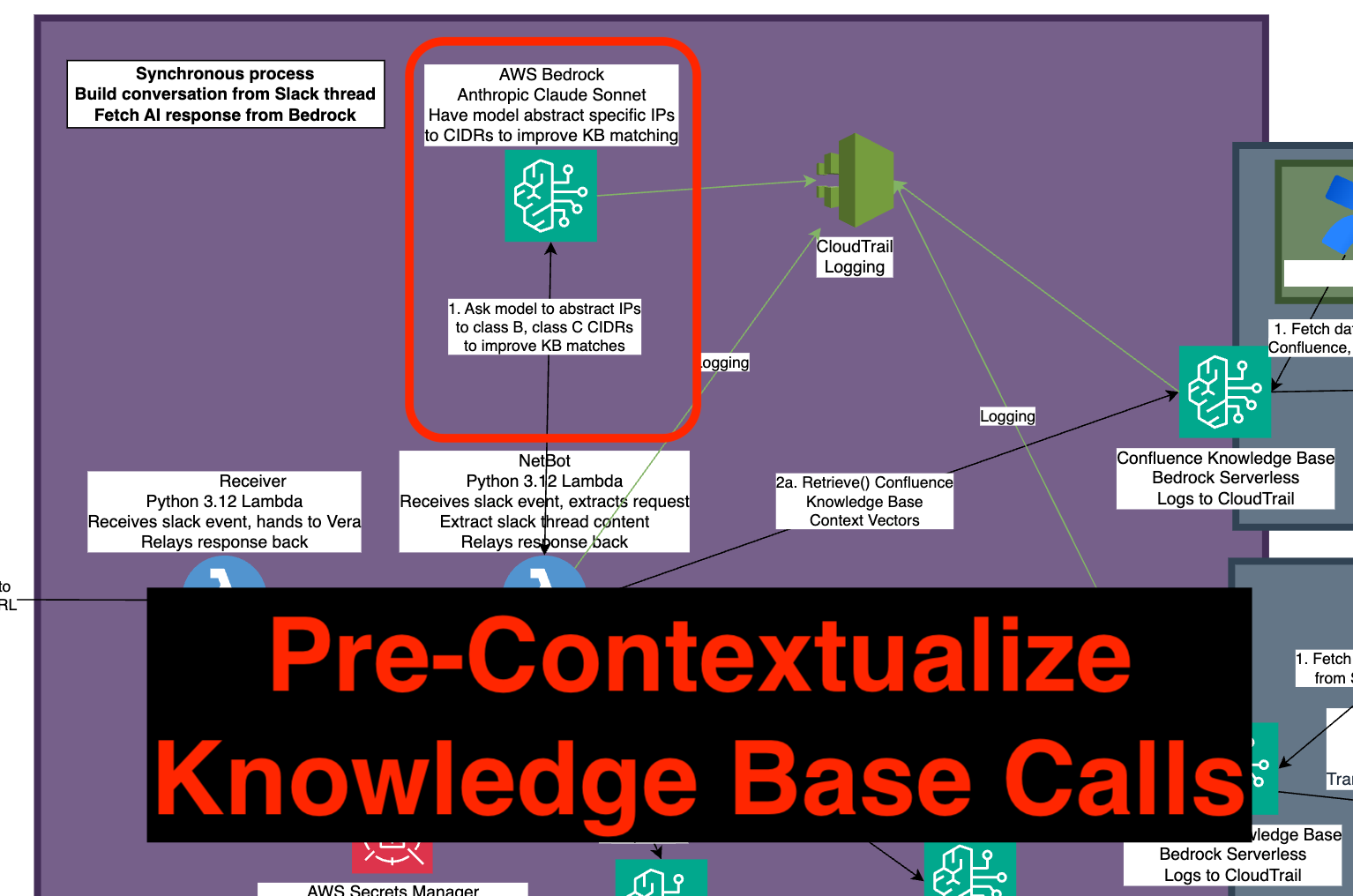
This sounds really abstract, so lets add an example. I’m building “NetBot”, a tool to help answer the “is it the network?” type questions engineers ask all the time. This tool is both trained on our large general data store (Confluence) but also specifically on highly structured data (the iOS and ASA configs that filter traffic across our network).
When folks ask “does my VPN permit me to 1.2.3.4 host”, the knowledge base fails terribly - some/most network device rules don’t permit to a host, they permit to a CIDR, or a whole VPC/vNet. Knowledge base fetching using RAG generally isn’t smart enough to figure that out, so we have a model with system prompt instructions to:
Assistant should find any specific (/32) IPs in the thread, and specify the class B and Class C CIDRs for the network.
Assistant should provide no other information.
If there are no IPs, assistant must not respond at all.
With that context, the NetBot knowledge base results are markedly more related to the question, since they are now able to find rules that would permit or deny the flow, but which don’t have an exact keyword match.
Notably, NetBot isn’t finished, and I may transition the whole thing to agentic skills (via MCP?) in order to get it working to a level I want it to. However, this pattern has proven useful for all sorts of other use cases, so I wanted to share how it might improve your AI architectures.
Lets walk through how this is implemented - I wrote it all out so you can easily steal borrow it!
Implementation - Constants
Keep reading with a 7-day free trial
Subscribe to Let's Do DevOps to keep reading this post and get 7 days of free access to the full post archives.