

🔥Let’s Do DevOps: Build AWS ECS on Fargate Using a Full-Featured Terraform Module

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
I’ve spent the last week working on building a generalized AWS ECS module for Terraform so my team can easily deploy containers on Fargate, AWS’s provided container compute.
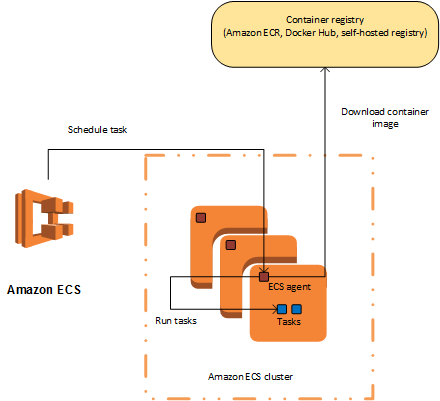
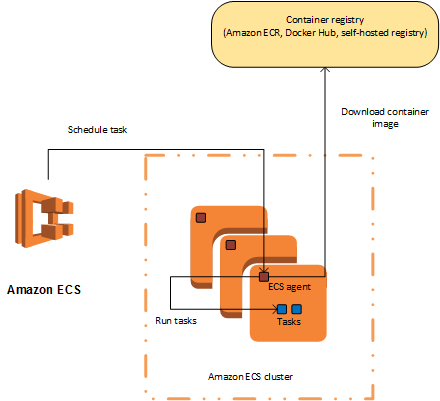
There are lots of resources available from both Hashi and AWS on how to deploy an ECS cluster, but they mostly focus just on the ECS resource. They don’t help you configure the other required resources, like:
Cloudwatch log group to store logs
“Execution” IAM role used to access resources and stage task resources
Generate IAM policy for access to secrets, S3 buckets, and KMS keys and link to Execution IAM role (which I build dynamically using really cool terraform
forloops and IAM data policy constructors)An ECS task definition, that instructs the builder on how to launch, size, environments
An ECS cluster logical object
An ECS service to link tasks with cluster
An app auto-scale target to be used with auto-scaling actions
Scheduled actions to use AWS-side cron to increase or decrease pool sizes (or rebuild pool from scratch, as I’ll go over)
All of these resources above are critical to making your ECS deployment successful, and unfortunately, there isn’t a good module that covers all of this. But I wrote one, and I want to give it away!
The code is linked at the end of this article if you want to skip there, and I’m going to go over each part, why it’s built that way, and show you how to customize your deployment for your environment.
First, let’s go over how we’d call this module, then you’ll get to compare it with what the module does (it’s a lot!)
Calling the Module
First, let’s go over what the module gives us, and at the end, I’ll show you how little information you need to provide to it for it to deploy the full ECS solution.
Finding Secret KMS CMK ARN
Now that’s a lot of acronyms in a row! We want our execution process that launches our container to be able to get to any secrets, as well as the KMS CMK (Customer Managed Key) that are used to encrypt them. To do that, we need to the ARN of the CMK, which we can lookup using this data block, paired with the secret IAM I’ll go over below.
| data "aws_secretsmanager_secret" "kms_cmk_arn" { | |
| arn = "kms_cmk_arn" # We look up the secret via ARN, and find the KMS CMK's ARN, referenced below | |
| } |
Calling the Module
This is the entire module call. Keep that in mind as we go over the many resources and configuration we build in the next section as we go over the module.
First, we set an ecs_name which is a designator to keep the resources separate and name them something a human would recognize. This permits launching the module several times (many times!) in the same account and region.
Then we pass the ECR URL — the location of our image to launch.
Then we pass the task variables (non-secret, strings) and the task secret variables (secret, ARN to secret in secrets manager).
Then we pass a complex object called execution_iam_access. It contains the ARNs of any resources our execution IAM role will need to get to. I go over this in detail in the module section below.
Then we pass the ARN of the task role that the container should use.
Finally, we pass in the subnets and security groups our FARGATE cluster and container should use.
| module "Ue1TiGitHubBuilders" { | |
| source = "./modules/ecs_on_fargate" | |
| ecs_name = "ResourceGroupName" # Name to use for customizing resources, permits deploying this module multiple times with different names | |
| image_ecr_url = "url_of_ECR" # URL of the container repo where image is stored | |
| task_environment_variables = [ # List of maps of environment variables to pass to container when it's spun up | |
| { name : "ENV1", value : "env_value1" }, # Remember these are clear-text in the console and via CLI | |
| { name : "ENV2", value : "env_value2" } | |
| ] | |
| task_secret_environment_variables = [ #Use this secret block for secrets, passkeys, etc. | |
| { name : "SECRET", valueFrom : "secrets_manager_secret_arn" } # Note we're using 'valueFrom' here, which accepts a secrets manager ARN rather than plain-text secret | |
| ] | |
| execution_iam_access = { | |
| secrets = [ | |
| "secrets_manager_secret_arn" # ARN of secret to grant access to | |
| ] | |
| kms_cmk = [ | |
| data.aws_secretsmanager_secret.kms_cmk_arn.kms_key_id # For secret encrypted with CMK, find CMK ARN and grant access | |
| ] | |
| s3_buckets = [ | |
| "s3_bucket_arn" # S3 bucket ARN to grant access to | |
| ] | |
| } | |
| task_role_arn = "arn_of_task_role" # This role is used by the container that's launched | |
| service_subnets = [ # A list of subnets to put the fargate and container into | |
| var.subnet1_id, | |
| var.subnet2_id, | |
| ] | |
| service_sg = [ # A list of SGs to assign to the container | |
| var.sg_id, | |
| ] | |
| } |
And that’s it. If you’re used to servers this might seem like a lot, but it actually simplifies the resource configuration a great deal.
Now let’s delve into what the module is doing based on all the information we sent it above.
Module Components
CloudWatch Logs
First of all, we build a log group in cloudwatch to store our ECS logs.
| # Cloudwatch to store logs | |
| resource "aws_cloudwatch_log_group" "CloudWatchLogGroup" { | |
| name = "${var.ecs_name}LogGroup" | |
| tags = { | |
| Terraform = "true" | |
| Name = "${var.ecs_name}LogGroup" | |
| } | |
| } |
Execution IAM Role
AWS ECS requires what it terms an “execution” IAM role, which is the IAM role used to gather all the elements needed to launch the container image. For instance, this role usually gathers permissions to access the ECR to grab the image, the secrets manager to pull secrets (and pass them to the container), and the KMS in order to get keys to decrypt secrets.
| resource "aws_iam_role" "ExecutionRole" { | |
| name = "${var.ecs_name}ExecutionRole" | |
| assume_role_policy = jsonencode({ | |
| Version = "2012-10-17" | |
| Statement = [ | |
| { | |
| Action = "sts:AssumeRole" | |
| Effect = "Allow" | |
| Sid = "" | |
| Principal = { | |
| Service = "ecs-tasks.amazonaws.com" | |
| } | |
| }, | |
| ] | |
| }) | |
| tags = { | |
| Name = "${var.ecs_name}ExecutionRole" | |
| Terraform = "true" | |
| } | |
| } |
We attach that role to a built-in AWS policy called “AmazonECSTaskExecutionRolePolicy” which grants common ECS execution rights, like accessing ECRs and writing to CloudWatch.
| resource "aws_iam_role_policy_attachment" "ExecutionRole_to_ecsTaskExecutionRole" { | |
| role = aws_iam_role.ExecutionRole.name | |
| policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy" | |
| } |
IAM Policies — Preprocessing ARNs and Policy Construction
IAM policies do incredible stuff, but they can be a bit boring and technical to work with. I worked hard for many hours to build a constructor that would make this process incredibly easy. Big shout out to Jamie Phillips on the HashiCorp Ambassadors group, who helped point me in the right direction.
First let’s start with what our parents would pass to this module. The following is pithy and most importantly: very easy to understand. Consumers of this module don’t need to write IAM policies and know which permissions, to grant, they just need to list out a few ARNs in the right blocks and the module will build them policies and attach them, all automatically.
| execution_iam_access = { | |
| secrets = [ | |
| "secrets_manager_secret_arn" | |
| ] | |
| kms_cmk = [ | |
| data.aws_secretsmanager_secret.kms_cmk_arn.kms_key_id | |
| ] | |
| s3_buckets = [ | |
| "s3_bucket_arn" | |
| ] | |
| } |
Extracting them is no easy feat, however. First we need to loop over this map of lists and extract all the proper lists — that’s the first for loop. Then within that loop, we do another for loop, this time grabbing each secret listed there and adding a * at the end, as the IAM policy we’ll build below requires.
Note that we also have an if there which helps us select only the list used for holding secrets, rather than s3_buckets or kms cmk keys.
Note also that all of this is within a flatten block (to remove nested lists) and also a try block. This means that if the caller didn’t include any secrets at all this first stanza will error out, and it’ll choose the second stanza, which is a known quantity — an empty set. We use the code below to handle this situation without problems.
| locals { | |
| # Find all secret ARNs and output as a list | |
| execution_iam_secrets = try( | |
| flatten([ | |
| for permission_type, permission_targets in var.execution_iam_access : [ | |
| for secret in permission_targets : "${secret}*" | |
| ] | |
| if permission_type == "secrets" | |
| ]), | |
| # If nothing provided, default to empty set | |
| [], | |
| ) |
There are a few of these, all preparing lists of each resource target we’ll require for our IAM policies below.
Next we create a data block to help us build our IAM policy document. It’s predicated on a count, and note that empty set that we used above in our locals try block if the caller didn’t send us any secrets.
Note how we’re able to just pass resources on our local.execution_iam_secrets list of resources that we prepared ahead of time. This looks very clean, and is much simpler than the locals try/flatten/for/for loops above.
After that we create the IAM role policy, an embedded policy under the execution role, and link it to the data document we created.
| data "aws_iam_policy_document" "ecs_secrets_access" { | |
| count = local.execution_iam_secrets == [] ? 0 : 1 | |
| statement { | |
| sid = "${var.ecs_name}EcsSecretAccess" | |
| resources = local.execution_iam_secrets | |
| actions = [ | |
| "secretsmanager:GetSecretValue", | |
| ] | |
| } | |
| } | |
| resource "aws_iam_role_policy" "ecs_secrets_access_role_policy" { | |
| count = local.execution_iam_secrets == [] ? 0 : 1 | |
| name = "${var.ecs_name}EcsSecretExecutionRolePolicy" | |
| role = aws_iam_role.ExecutionRole.id | |
| policy = data.aws_iam_policy_document.ecs_secrets_access[0].json |
There are several sets of those, and based on the above design it’s a great extensible model for any other types of permissions you’d like to grant a role in any context. It does build a separate role policy for each type of permission, which won’t be scalable beyond 10 or so. However, I’m unable to find a way to concat policy documents together in a safe way. If you’ve figured out this problem please let me know!
ECS Task Definition
Next, we construct the ECS task definition, which contains a lot of the meat of what you imagine when you imagine “launching a container”.
Note we have hard-coded FARGATE here, my use case doesn’t require ec2-backed builders. If yours does, you’ll need to make this a variable and add some other logic. Note the fargate cpu and memory options, which default to 1024 CPU and 2048 memory, but can be overridden to be larger if required.
Then we have the container definition, which is almost entirely constructed for us based on information we’ve provided. We default to the :latest tag in the ECR, feel free to over-ride that in your caller if you want to manage versions in a more enterprise-friendly way. You can also over-ride the container CPU and memory requirements — make sure they don’t require more than your FARGATE cluster has available, or the container won’t be able to launch.
We also pass in the environment (strings) and secret environment (references to secrets manager) information. The ECS execution process will gather all this information on its way to launching the container.
Then we tack on the logging information at the end.
| resource "aws_ecs_task_definition" "ecs_task_definition" { | |
| family = "${var.ecs_name}" | |
| execution_role_arn = aws_iam_role.ExecutionRole.arn | |
| task_role_arn = var.task_role_arn == null ? null : var.task_role_arn | |
| network_mode = "awsvpc" | |
| requires_compatibilities = ["FARGATE"] | |
| # Fargate cpu/mem must match available options: https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task-cpu-memory-error.html | |
| cpu = var.fargate_cpu | |
| memory = var.fargate_mem | |
| container_definitions = jsonencode( | |
| [ | |
| { | |
| name = "${var.ecs_name}" | |
| image = "${var.image_ecr_url}:${var.image_tag}" | |
| cpu = "${var.container_cpu}" | |
| memory = "${var.container_mem}" | |
| essential = true | |
| environment = var.task_environment_variables == [] ? null : var.task_environment_variables | |
| secrets = var.task_secret_environment_variables == [] ? null : var.task_secret_environment_variables | |
| logConfiguration : { | |
| logDriver : "awslogs", | |
| options : { | |
| awslogs-group : "${var.ecs_name}LogGroup", | |
| awslogs-region : "${data.aws_region.current_region.name}", | |
| awslogs-stream-prefix : "${var.ecs_name}" | |
| } | |
| } | |
| } | |
| ] | |
| ) | |
| tags = { | |
| Name = "${var.ecs_name}" | |
| } | |
| } |
ECS Cluster
We create an ECS cluster logical entity. Interestingly, this doesn’t have much information at all — it only says what services to lean on to launch the compute. In this case, I’ve hard-coded FARGATE to make life easy for us.
| resource "aws_ecs_cluster" "fargate_cluster" { | |
| name = "${var.ecs_name}Cluster" | |
| capacity_providers = [ | |
| "FARGATE" | |
| ] | |
| default_capacity_provider_strategy { | |
| capacity_provider = "FARGATE" | |
| } | |
| } |
ECS Service Definition
Next, we define the ECS service. This service runs all the time and is able to launch and auto-heal our tasks if/when they die or are cycled out.
Note that we start out with a desired_count for how many task instances we want to launch, but we also ignore this value in future runs — we will either update this manually or via scheduled automation, which we’ll build next.
| resource "aws_ecs_service" "ecs_service" { | |
| name = "${var.ecs_name}Service" | |
| cluster = aws_ecs_cluster.fargate_cluster.id | |
| task_definition = aws_ecs_task_definition.ecs_task_definition.arn | |
| desired_count = var.autoscale_task_weekday_scale_down | |
| launch_type = "FARGATE" | |
| platform_version = "LATEST" | |
| network_configuration { | |
| subnets = var.service_subnets | |
| security_groups = var.service_sg | |
| } | |
| # Ignored desired count changes live, permitting schedulers to update this value without terraform reverting | |
| lifecycle { | |
| ignore_changes = [desired_count] | |
| } | |
| } |
ECS App AutoScale Target
We want to use cron jobs to scale our service up and down based on known traffic and compute requirements. Even if you want to scale based on resource utilization, you’ll require this particular resource. It provides a target for auto-scaling services of any variety (scheduled or resource utilization driven).
They don’t do anything like that themselves, though. For that, we need another resource.
| resource "aws_appautoscaling_target" "ServiceAutoScalingTarget" { | |
| count = var.enable_scaling ? 1 : 0 | |
| min_capacity = var.autoscale_task_weekday_scale_down | |
| max_capacity = var.autoscale_task_weekday_scale_up | |
| resource_id = "service/${aws_ecs_cluster.fargate_cluster.name}/${aws_ecs_service.ecs_service.name}" # service/(clusterName)/(serviceName) | |
| scalable_dimension = "ecs:service:DesiredCount" | |
| service_namespace = "ecs" | |
| lifecycle { | |
| ignore_changes = [ | |
| min_capacity, | |
| max_capacity, | |
| ] | |
| } | |
| } |
ECS AutoScale Scheduling
We first predicate all this on an enable_scaling variable, so you can happily disable this if you want. Then we set a timezone (PST, Los_Angeles in America), and set a cron of 5 a.m. PST Monday-Friday.
There are 3 of these available to do the following actions:
Scale-up at 5 a.m. at the beginning of each weekday
Scale down at 8 p.m. at the end of each weekday
Scale to 0 each night at midnight — this allows us to guarantee no host has been up for longer than 24 hours, which (if we’ve built this container within the last 24 hours) means it will always be running the new version
Scale to 1 each night at 5 minutes after midnight — This permits us to have minimal coverage over night-times
| resource "aws_appautoscaling_scheduled_action" "WeekdayScaleUp" { | |
| count = var.enable_scaling ? 1 : 0 | |
| name = "${var.ecs_name}ScaleUp" | |
| service_namespace = aws_appautoscaling_target.ServiceAutoScalingTarget[0].service_namespace | |
| resource_id = aws_appautoscaling_target.ServiceAutoScalingTarget[0].resource_id | |
| scalable_dimension = aws_appautoscaling_target.ServiceAutoScalingTarget[0].scalable_dimension | |
| schedule = "cron(0 5 ? * MON-FRI *)" #Every weekday at 5 a.m. PST | |
| timezone = "America/Los_Angeles" | |
| scalable_target_action { | |
| min_capacity = var.autoscale_task_weekday_scale_up | |
| max_capacity = var.autoscale_task_weekday_scale_up | |
| } | |
| } |
Conclusion
Thanks so much for coming along with me as I’ve walked through what this module does. AWS ECS provides a moderately intuitive way to launch and manage container clusters, and with some module support, you’ll be launching your own ECS clusters in no time.
Find the code here:
KyMidd/Terraform_AwsEcsOnFargate_CompleteModule
Contribute to KyMidd/Terraform_AwsEcsOnFargate_CompleteModule development by creating an account on GitHub.github.com
Good luck out there!
kyler