
🔥Building a Slack Bot with AI Capabilities - From Scratch! Part 3: Connect Slack and Claude Sonnet with Ngrok🔥
aka, Lets get this Slack AI talking with A LOT of python

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
These articles are supported by readers, please consider subscribing to support me writing more of these articles <3 :)
This article is part of a series of articles, because 1 article would be absolutely massive.
Part 1: Covers how to build a slack bot in websocket mode and connect to it with python
Part 3 (this post): We’ll connect our slack bot with Bedrock locally using python3 with ngrok so slack users can have conversations with AI
Part 4: How to convert your local script to an event-driven serverless, cloud-based app in AWS Lambda
Part 7: Streaming token responses from AWS Bedrock to your AI Slack bot using converse_stream()
Part 8: ReRanking knowledge base responses to improve AI model response efficacy
Part 9: Adding a Lambda Receiver tier to reduce cost and improve Slack response time
Hey all!
In part 1, we build a slack bot and connected it to a local python instance. In part 2, we deployed an AWS Bedrock AI with guardrails, and connected to it with local python.
In this article, we’re going to connect the two. First, we’ll get our slack bot listening on a local port. Then we’ll get ngrok going, which is a tool that’ll help proxy a public request to our private port, and let us receive direct webhook messages from slack when folks tag our bot - it’s how we’ll deploy when we’re properly in production, so testing it out locally is a great idea.
And then we’ll connect both our message and the slack thread information to our AI request, so we can complete a whole circuit. By the time this article is done, we’ll have a working AI slack bot.
I’ve started to call this AI bot Vera, and use she/her pronouns by convention

Notably, this awesome slack bot will depend on ngrok, a third party (that we have to assume is insecure, even if the company is amazing and isn’t), and will depend on your computer remaining on and this terminal remaining open.
In the next (and last!) part, we’re going to convert the whole shebank to an AWS Lambda so we don’t have to keep anything running locally on our computer.
If you’d rather skip over all this exposition and just read the code, you can do so here:
https://github.com/KyMidd/SlackAIBotServerless/blob/master/python/devopsbot.py
This is going to be awesome. Let’s get started.
Constants
I thought about implementing the slack part first, and then the Bedrock AI part, but they’re so interdependent we’re going to combine them. I’ll call out where the dependencies are.
First of all, lets import some tools. We need os, logging to run the app - read secrets, log logs. We need boto3 to integrate with Bedrock AI, as well as json and base64 to package and unpack the requests and responses. And we need requests to fetch secrets from AWS Secrets Manager as well as grab some info from Slack to build our thread content (more on that later).
And we need slack_bolt and the various components to integrate with Slack. We’ll also go into that deeply below.
| # Global imports | |
| import os | |
| import logging | |
| import boto3 | |
| import json | |
| import base64 | |
| import requests | |
| # Slack app imports | |
| from slack_bolt import App | |
| from slack_bolt.adapter.socket_mode import SocketModeHandler # Required for socket mode, used in local development | |
| from slack_bolt.adapter.aws_lambda import SlackRequestHandler |
Next up lets define some constants. These are the user-configurable options that we might change in the future. It makes sense to pull these out of our code and define them at the top for the ease of the humans maintaining this stuff.
On line 2, we set the ID of the model we’re using. This will change over time as Anthropic releases new versions of their AIs, and Bedrock implements them. For now we’ll pin it.
On line 3, this is the version of the Anthropic AI. This basically doesn’t change, but we set it here so we can modify if we ever want to.
On line 4, we set the temperature of our model. We set this pretty low, since we don’t want our model to flat out make stuff up. I’m tempted to set this even lower. The range is 0.0 (cannot extrapolate at all) —> 1.0 (pure creativity, makes up tons of stuff).
On line 5, we set the name of the json-encoded secret in Secrets Manager we’ll fetch in us-east-1 region. There are a few secrets we’ll grab from it, we’ll talk more about that when we get there.
On line 6-8, we talk about guardrails. We’ll enable that when we’re running in lambda, but when we’re local, we don’t need it.
On line 11, we set the region of our model. I tested out us-east-1, and it was broken frequently, so I deployed to us-west-2, and it’s worked since. Your mileage may vary.
On line 14, we define an important set of instructions. This model guidance is injected for every conversation, and is immutable for the conversation. The AI request is governed by these requests. If you have company policies, or other guidance (“we’re in the financial space, and must abide by financial laws”, etc.) this is where you’ll set that. I imagine this will change pretty rapidly when you implement it in your enterprise.
| # Specify model ID and temperature | |
| model_id = 'anthropic.claude-3-5-sonnet-20241022-v2:0' | |
| anthropic_version = "bedrock-2023-05-31" | |
| temperature = 0.2 | |
| bot_secret_name = "DEVOPSBOT_SECRETS_JSON" | |
| enable_guardrails = False # Won't use guardrails if False | |
| guardrailIdentifier = "xxxxxxxxxx" | |
| guardrailVersion = "DRAFT" | |
| # Specify the AWS region for the AI model | |
| model_region_name = "us-west-2" | |
| # Model guidance, shimmed into each conversation as instructions for the model | |
| model_guidance = """Assistant is a large language model trained to provide the best possible experience for developers and operations teams. | |
| Assistant is designed to provide accurate and helpful responses to a wide range of questions. | |
| Assistant answers should be short and to the point. | |
| Assistant uses Markdown formatting. When using Markdown, Assistant always follows best practices for clarity and consistency. | |
| Assistant always uses a single space after hash symbols for headers (e.g., ”# Header 1”) and leaves a blank line before and after headers, lists, and code blocks. | |
| For emphasis, Assistant uses asterisks or underscores consistently (e.g., italic or bold). | |
| When creating lists, Assistant aligns items properly and uses a single space after the list marker. For nested bullets in bullet point lists, Assistant uses two spaces before the asterisk (*) or hyphen (-) for each level of nesting. | |
| For nested bullets in numbered lists, Assistant uses three spaces before the number and period (e.g., “1.”) for each level of nesting. | |
| """ |
There’ll be a lot of function calls that we call from our main function. To help make sense of this, we’ll try to follow along the chain of logic that happens here. When we launch our app, it has to fetch some secrets from secrets manager in order to run. You can inject these locally instead of fetching them, but I think fetching them is easier.
Let’s talk about how this secret is stored. This json payload is the secret that’s stored in Secrets Manager in us-east-1 region.
First, we have the Azure OpenAI API Key - this is used to authenticate to AWS Bedrock to make AI requests.
On line 3, the Slack Bot Token, which starts with xoxb. This is generated when you install your Slack App into an Org. It notably doesn’t change if you need to update permissions and reinstall the app.
On line 4, the Slack Signing Secret. This is unique to your Slack App.
| { | |
| "AZURE_OPENAI_API_KEY": "EcLTT2...REuB", | |
| "SLACK_BOT_TOKEN": "xoxb-34.....rOa", | |
| "SLACK_SIGNING_SECRET": "4b.....195" | |
| } |
Next lets go through the beginning of our main function. On line 5 we print out some simple logs to stdout - these will be logged to cloudwatch on each run, as well as your local terminal when running this locally.
On line 8, we fetch our secrets with the get_secret function. We pass in the name of the secret, as well as the region, “us-east-1”. I hard-coded it here, but feel free to update to whatever region you’d like.
Lets jump down to the function on line 17. We receive those values with the same name (this helps the humans keep things straight), and on line 20-21, we establish a client connection that can make calls to AWS secrets manager.
The on line 24 we try to get the value of a secret, and catch any errors on line 25.
On line 32, we decrypt the secret with its KMS key, and on line 38, we return the secret.
Remember, this is a json payload, so on line 11-13 we disambiguate the secret values from the json payload so they can be accessed directly.
Note that the json payload seems complex - why not just call each secret value directly? Well, it takes about 2 seconds PER SECRET to fetch them from secrets manager, which is wild. We have 3 secrets, so it’d be 6 seconds of waiting for the user just to get the secrets and START processing the response. Combining them saves us 4 seconds.
| # Main function | |
| if __name__ == "__main__": | |
| # Run in local development mode | |
| print("🚀 Local server starting starting") | |
| # Fetch secret package | |
| secrets = get_secret(bot_secret_name, "us-east-1") | |
| # Disambiguate the secrets with json lookups | |
| secrets_json = json.loads(secrets) | |
| token = secrets_json["SLACK_BOT_TOKEN"] | |
| signing_secret = secrets_json["SLACK_SIGNING_SECRET"] | |
| .... | |
| # Get GitHubPAT secret from AWS Secrets Manager that we'll use to start the githubcop workflow | |
| def get_secret(secret_name, region_name): | |
| # Create a Secrets Manager client | |
| session = boto3.session.Session() | |
| client = session.client(service_name="secretsmanager", region_name=region_name) | |
| try: | |
| get_secret_value_response = client.get_secret_value(SecretId=secret_name) | |
| except ClientError as e: | |
| # For a list of exceptions thrown, see | |
| # https://docs.aws.amazon.com/secretsmanager/latest/apireference/API_GetSecretValue.html | |
| print("Had an error attempting to get secret from AWS Secrets Manager:", e) | |
| raise e | |
| # Decrypts secret using the associated KMS key. | |
| secret = get_secret_value_response["SecretString"] | |
| # Print happy joy joy | |
| print("🚀 Successfully got secret", secret_name, "from AWS Secrets Manager") | |
| # Return the secret | |
| return secret |
Next lets register our slack app. This enables us to ingest a slack payload and understand what’s being sent to us, as well as format responses.
| # Main function | |
| if __name__ == "__main__": | |
| ... | |
| # Register the Slack handler | |
| print("🚀 Registering the Slack handler") | |
| app = create_app(token, signing_secret) | |
| # Initializes the slack app with the bot token and socket mode handler | |
| def create_app(token, signing_secret): | |
| return App( | |
| process_before_response=True, # Required for AWS Lambda | |
| token=token, | |
| signing_secret=signing_secret, | |
| ) |
Next we establish a boto3 client to talk to Bedrock for AI requests.
| # Main function | |
| if __name__ == "__main__": | |
| ... | |
| # Register the AWS Bedrock AI client | |
| print("🚀 Registering the AWS Bedrock client") | |
| bedrock_client = create_bedrock_client(model_region_name) | |
| # Create a Bedrock client | |
| def create_bedrock_client(region_name): | |
| return boto3.client("bedrock-runtime", region_name=region_name) |
Next in our main function we listen for two different event types:
Line 5 - an “app mention”, which is where someone does like @Vera to trigger our bot.
Line 17 - a “message", which is where someone direct messages (DMs) our bot.
These are almost duplicates - I suppose we could move this functionality to a function, but that seems silly when it’s only a few lines of instructions.
For each, we do two things:
First, line 8 - we check for duplicate events. This is all sorts of trash events like re-sends (slack assumes your receiver has died if you don’t respond within 3 seconds), and others, we’ll talk about more shortly. If this function returns True, we generate an http 200 and log the discard.
Then on line 14, we handle our message event. This means we thing this is a valid query to our AI from the slack app, and we need to extract it, build the context, pass it to the AI, and get a response. There’s a lot there, we’ll go into that in depth below also.
| # Main function | |
| if __name__ == "__main__": | |
| ... | |
| # Responds to app mentions | |
| @app.event("app_mention") | |
| def handle_app_mention_events(client, body, say, req, payload): | |
| # Check for duplicate event or trash messages, return 200 and exit if detected | |
| if check_for_duplicate_event(req.headers, payload): | |
| return generate_response( | |
| 200, "❌ Detected a re-send or edited message, exiting" | |
| ) | |
| # Handle request | |
| handle_message_event(client, body, say, bedrock_client, app, token) | |
| # Respond to file share events | |
| @app.event("message") | |
| def handle_message_events(client, body, say, req, payload): | |
| # Check for duplicate event or trash messages, return 200 and exit if detected | |
| if check_for_duplicate_event(req.headers, payload): | |
| return generate_response( | |
| 200, "❌ Detected a re-send or edited message, exiting" | |
| ) | |
| # Handle request | |
| handle_message_event(client, body, say, bedrock_client, app, token) |
First lets talk about how we check for duplicates. The initial need for this is because the Slack API servers assume your responder has died if it doesn’t respond within 3 seconds. For some very simple AI requests, we can do the whole thing and respond in 3 seconds (remember, just fetching the secret takes 2 seconds!) which doesn’t matter a ton in local mode, but in event-driven serverless mode, that’s a tall order.
Really, we should be doing a tiered lambda architecture where the front-end lambda receives the request, and immediately responds with an http/200. Due to low volume and “build this fast with duct tape” mentality, I didn’t build that (yet?), so we often don’t respond within the 3 second time-frame.
So on line 11, we check if this is a retry send, which is the “x-slack-retry-num” header value (which isn’t present at all on the first message), and if it’s there, we throw this away and return.
I also had a few different types of events shake out over testing this the past few weeks. Some weird behavior I want to handle elegantly:
On line 17 - if someone edits their message, the Slack API sends the request again, and without this handler, Vera responds again, each time someone edits their message. That’s kind of weird behavior, and maybe we should be having Vera edit her message responses each time, but instead of that, we just throw it away.
On line 22, if the event is a “bot” (often, Vera herself) sending a message in the thread, we throw it away. In the future, if you want to integrate bots to call your AI, you’ll have to modify this logic.
On line 28, we check if the event is that a message that tags vera is “deleted”, which Slack again sends as a new request with a special payload flag. So we check for that flag (“tombstoned”, a super cool flag name) and throw it away.
I’m sure I’ll keep finding edge cases where we want to just throw away the response instead of responding, and so I pulled all these edge cases into one function call so it’s easier to follow.
| # Check for duplicate events | |
| def check_for_duplicate_event(headers, payload): | |
| # Debug | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 Headers:", headers) | |
| print("🚀 Payload:", payload) | |
| # Check headers, if x-slack-retry-num is present, this is a re-send | |
| # Really we should be doing async lambda model, but for now detecting resends and exiting | |
| if "x-slack-retry-num" in headers: | |
| print("❌ Detected a re-send, exiting") | |
| logging.info("❌ Detected a re-send, exiting") | |
| return True | |
| # Check if edited message in local development | |
| if "edited" in payload: | |
| print("Detected a message edited event, responding with http 200 and exiting") | |
| return True | |
| # If bot_id is in event, this is a message from the bot, ignore | |
| if "bot_id" in payload: | |
| print("Message from bot detected, discarding") | |
| logging.info("Detected a duplicate event, discarding") | |
| return True | |
| # If body event message subtype is tombstone, this is a message deletion event, ignore | |
| if ( | |
| "subtype" in payload.get("message", {}) | |
| and payload["message"]["subtype"] == "tombstone" | |
| ): | |
| print("Detected a tombstone event, discarding") | |
| logging.info("Detected a tombstone event, discarding") | |
| return True |
Next lets walk through how we handle a message event. There’s a TON here so we’ll break it into parts. Remember, at this section this is a payload event that we think we need to turn into an AI request, send, and relay a response back to Slack.
First, we receive a ton of information:
client - The Slack App client
body - The body of the message, including all headers
say - a function of the slack app which permits us to respond
bedrock_client - the client we’ll use to talk to Bedrock to make AI requests
app - the slack app context
token - the authentication token for our slack app
First on line 4, we extract the user_id of whoever is talking to Vera. Vera doesn’t tell us their username or real name, we’ll look that up later with this ID string.
On line 5, we extract the event - this is what happened to make the Slack App send us a message
The on line 8, we check to see if this slack app tag is part of a thread in slack by checking for the thread timestamp. This is only present if we’re in a slack thread.
We’re basically going to exactly map over the slack thread context (image files, comments for anyone) over to the AI request conversation. This permits all context to be passed on to the AI, and it to respond intelligently to multiple speakers. More on that soon.
We want to build a conversation to pass to our AI, so we establish an empty set on line 11.
On line 15 - if we’re in a slack thread, we get a list of messages on line 18. We’ll walk through each message next.
| # Common function to handle both DMs and app mentions | |
| def handle_message_event(client, body, say, bedrock_client, app, token): | |
| user_id = body["event"]["user"] | |
| event = body["event"] | |
| # Determine the thread timestamp | |
| thread_ts = body["event"].get("thread_ts", body["event"]["ts"]) | |
| # Initialize conversation context | |
| conversation = [] | |
| # Check to see if we're in a thread | |
| # If yes, read previous messages in the thread, append to conversation context for AI response | |
| if "thread_ts" in body["event"]: | |
| # Get the messages in the thread | |
| thread_ts = body["event"]["thread_ts"] | |
| messages = app.client.conversations_replies( | |
| channel=body["event"]["channel"], ts=thread_ts | |
| ) |
Continuing the same function call, we start to walk through every message (line 7) in the slack thread. Slack permits an UNLIMITED number of responses in threads, which is crazy pants.
For every message, we extract the thread content and check if there are any unsupported file types found, with a call to another function, “build_conversation_content", which we send the individual message, and a slack app token. We’ll go over that function call next.
On line 14 (and in lots of other places), there are some debugs that can be turned on if you’d like. It checks for an environmental var, so it’s easy to turn on for your local app or a lambda once we convert it.
On line 18, we check if the thread conversation is still empty - this can happen if the user sends an unsupported doc, with no text.
Interestingly, Slack permits users to send a message with a) text b) any number of files or c) text AND any number of files. Because of that, we have to handle all those edge cases elegantly.
On line 23, we check if the message came from a bot. If yes, we build the json structure Claude Sonnet on Bedrock expects. Calling out who is saying stuff helps Vera tell if she said something or if someone else said something.
On line 37, if the user didn’t come from a bot, then it came from a user, and we build the json payload that Claude Sonnet on Bedrock expects.
| # Common function to handle both DMs and app mentions | |
| def handle_message_event(client, body, say, bedrock_client, app, token): | |
| .... | |
| if "thread_ts" in body["event"]: | |
| .... | |
| # Iterate through every message in the thread | |
| for message in messages["messages"]: | |
| # Build the content array | |
| thread_conversation_content, unsupported_file_type_found = ( | |
| build_conversation_content(message, token) | |
| ) | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 Thread conversation content:", thread_conversation_content) | |
| # Check if the thread conversation content is empty. This happens when a user sends an unsupported doc type only, with no message | |
| if thread_conversation_content != []: | |
| # Conversation content is not empty, append to conversation | |
| # Check if message came from the bot | |
| # We're assuming the bot only generates text content, which is true of Claude v3.5 Sonnet v2 | |
| if "bot_id" in message: | |
| conversation.append( | |
| { | |
| "role": "assistant", | |
| "content": [ | |
| { | |
| "type": "text", | |
| "text": message["text"], | |
| } | |
| ], | |
| } | |
| ) | |
| # If not, the message came from a user | |
| else: | |
| conversation.append( | |
| {"role": "user", "content": thread_conversation_content} | |
| ) | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print( | |
| "🚀 State of conversation after threaded message append:", | |
| conversation, | |
| ) |
Lets take a small detour to the build_conversation_content() function, which we called above. This is also a pretty large function, so we’ll split it in half.
We receive the json payload that contains our message content, as well as a token for the slack app.
On line 5, we initialize a canary variable that we haven’t yet found an unsupported file type, like PDF (at date of publication) or DOCX, etc.
I plan to rewrite this whole thing to use the converse() API for Bedrock so I can support PDF, DOCX, Excel, etc. For now we support a few image file types, and text only. It’s a bit annoying the AWS docs weren’t more opinionated on which API to choose when building this so I could have done that from the beginning.
On line 8, we create an empty array for the content of our conversation. “Conversations” are made up of a series of “content” blocks that represent a single speaker saying words (optionally) or sending files (optionally).
On line 11 we extract the user_id again, and then on line 14 we go get that user’s information. That helps us find the user’s full real name, which we extract on line 20 - 21.
Having the user’s real name lets us prepend this to each message in a thread that we generate for Claude Sonnet to read. This helps our AI tell who is speaking, and identify multiple speakers by name, which can help to contextualize and understand if folks are disagreeing or having different opinions.
On line 23, called out we should add support for pronouns in the future. Right now Vera calls everyone “they”, and it’d be great to be able to identify pronouns for speakers so Vera can speak more like a human.
On line 26, we check to see if there is any text in this message (remember, Slack permits you to send just any number of files, without any text).
If there is any text, on line 31, we append the written words to the content block, but not before prepending the real name of the speaker so Vera can understand who is saying what.
| # Function to build the content of a conversation | |
| def build_conversation_content(payload, token): | |
| # Initialize unsupported file type found canary var | |
| unsupported_file_type_found = False | |
| # Initialize the content array | |
| content = [] | |
| # Identify the user's ID | |
| user_id = payload["user"] | |
| # Find the user's information | |
| user_info = requests.get( | |
| f"https://slack.com/api/users.info?user={user_id}", | |
| headers={"Authorization": "Bearer " + token}, | |
| ) | |
| # Identify the user's real name | |
| user_info_json = user_info.json() | |
| user_real_name = user_info_json["user"]["real_name"] | |
| # TODO: Add support for pronouns, if returned in user payload. For now, everyone is nonbinary | |
| # If text is not empty, and text length is greater than 0, append to content array | |
| if "text" in payload and len(payload["text"]) > 1: | |
| # If debug variable is set to true, print the text found in the payload | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 Text found in payload: " + payload["text"]) | |
| content.append( | |
| { | |
| "type": "text", | |
| # Combine the user's name with the text to help the model understand who is speaking | |
| "text": f"{user_real_name} says: {payload['text']}", | |
| } | |
| ) |
Lets look at the second half of how we’re building conversation content blocks. We’ve just looked at adding text to each message. Now lets walk through the “any number of files” that might be attached to the message in the thread.
On line 5, check if there are any files.
On line 8, iterate through each one found.
On line 13, we check the mimetype in the file’s information, according to slack. Without the .converse() API, we can only support a handfull of image file types, so we check to see if it’s a supported one.
Slack doesn’t actually send you the file binary in the webhook (that’d be so inefficient!), instead it provides some URLs that you can use to fetch the files. So we extract the file URL on line 20, then go get it on line 23.
Bedrock doesn’t permit us to send binary files via a json POST, so we have to base64 encode the binary image file, which we can do on line 28.
On line 31, 42, we check the file type and then build the file into the content map we’ll inject into the conversation.
Line 55 is only triggered if the file is an unsupported type. I build this so if someone includes several different file types, and some are supported, and some aren’t, the file which are supported are built into the conversation content, and the unsupported files aren’t, effectively telling Vera to discard/ignore those files.
We do set the canary variable that there is an unsupported file type in the thread, and we directly post back to Slack if that is found.
Then on line 60 we return the conversation content block (of which there are potentially A LOT of), and the canary var if we found unsupported doc types in the message.
| # Function to build the content of a conversation | |
| def build_conversation_content(payload, token): | |
| .... | |
| # If the payload contains files, iterate through them | |
| if "files" in payload: | |
| # Append the payload files to the content array | |
| for file in payload["files"]: | |
| # Check the mime type of the file is a supported file type | |
| # Commenting out the PDF check until the PDF beta is enabled on bedrock | |
| # if file["mimetype"] in ['image/png', 'image/jpeg', 'image/gif', 'image/webp', 'application/pdf', 'application/msword', 'application/vnd.openxmlformats-officedocument.wordprocessingml.document']: | |
| if file["mimetype"] in [ | |
| "image/png", | |
| "image/jpeg", | |
| "image/gif", | |
| "image/webp", | |
| ]: | |
| # File is a supported type | |
| file_url = file["url_private_download"] | |
| # Fetch the file and continue | |
| file_object = requests.get( | |
| file_url, headers={"Authorization": "Bearer " + token} | |
| ) | |
| # Encode the image with base64 | |
| encoded_file = base64.b64encode(file_object.content).decode("utf-8") | |
| # Identify the mime type of the file, some require different file types when sending to the model | |
| if file["mimetype"] in [ | |
| "image/png", | |
| "image/jpeg", | |
| "image/gif", | |
| "image/webp", | |
| ]: | |
| file_type = "image" | |
| else: | |
| file_type = "document" | |
| # Append the file to the content array | |
| content.append( | |
| { | |
| "type": file_type, | |
| "source": { | |
| "type": "base64", | |
| "media_type": file["mimetype"], | |
| "data": encoded_file, | |
| }, | |
| } | |
| ) | |
| # If the mime type is not supported, set unsupported_file_type_found to True | |
| else: | |
| print(f"Unsupported file type found: {file['mimetype']}") | |
| unsupported_file_type_found = True | |
| continue | |
| # Return | |
| return content, unsupported_file_type_found |
Lets go back to where we’re building the conversation. At this point we’ve walked through every single message in the slack thread (even if there’s hundreds), and encoded them into the conversation.
Now on line 4, 12, 16 we encode the user’s message content block. The exact same logic applies, except this is the most recent message in the thread - the one that is tagging our slack bot.
On line 36, we check if the only content of this thread so far is an empty block, which means the only message so far is an unsupported doc type, with no text content. If yes, we post a message back.
This bug took forever to catch, like literally hours, ugh
| def handle_message_event(client, body, say, bedrock_client, app, token): | |
| .... | |
| # Build the user's part of the conversation | |
| user_conversation_content, unsupported_file_type_found = build_conversation_content( | |
| event, token | |
| ) | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 User conversation content:", user_conversation_content) | |
| # Check if the thread conversation content is empty. This happens when a user sends an unsupported doc type only, with no message | |
| if user_conversation_content != []: | |
| # Conversation content is not empty, append to conversation | |
| # Append the user's prompt to the conversation | |
| conversation.append( | |
| { | |
| "role": "user", | |
| "content": user_conversation_content, | |
| } | |
| ) | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 State of conversation after append user's prompt:", conversation) | |
| # Check if conversation content is empty, this happens when a user sends an unsupported doc type only, with no message | |
| # Conversation looks like this: [{'role': 'user', 'content': []}] | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 State of conversation before check if convo is empty:", conversation) | |
| if conversation == []: | |
| # Conversation is empty, append to error message | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 Conversation is empty, exiting") | |
| # Announce the error | |
| say( | |
| text=f"> `Error`: Unsupported file type found, please ensure you are sending a supported file type. Supported file types are: images (png, jpeg, gif, webp).", | |
| thread_ts=thread_ts, | |
| ) | |
| return | |
| ... |
We finally have build our entire conversation package out of content blocks, and its time to trigger our AI. We send our bedrock client context, as well as the conversation package we’ve built, to our function on line 3. We’ll go through that next.
We receive back a response, line 3, and utf-8 decode the response on line 6.
We read the response as json with json.loads() on line 11, and then extract the content of the AI’s response on line 16. The response from the AI should never be black, but we have some error handling just in case.
On line 27, we check if our canary var for unsupported docs is found, and if yes, we post a message to our slack thread that there is an unsupported doc type so folks are aware it’s responding based on incomplete information.
On line 36, we actually, finally say(), which means we post the AI response from Bedrock back to slack.
| def handle_message_event(client, body, say, bedrock_client, app, token): | |
| ... | |
| response = ai_request(bedrock_client, conversation) | |
| # Get response | |
| response_body = response["body"].read().decode("utf-8") | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 Response body:", response_body) | |
| # Conver to JSON | |
| response_json = json.loads(response_body) | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 response_json['content']:", response_json["content"]) | |
| # Check if response content is empty | |
| if response_json["content"] == []: | |
| print("🚀 Response content is empty, setting response_text to blank") | |
| response_text = "" | |
| else: | |
| # There is content in the response, set response_text to the text content | |
| response_text = response_json.get("content", [{}])[0].get("text", "") | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 response_text:", response_text) | |
| # Check if unsupported_file_type_found | |
| if unsupported_file_type_found == True: | |
| # If true, prepend error to response text | |
| response_text = f"> `Error`: Unsupported file type found, please ensure you are sending a supported file type. Supported file types are: images (png, jpeg, gif, webp).\n{ | |
| response_text}" | |
| if os.environ.get("VERA_DEBUG", "False") == "True": | |
| print("🚀 Response text after adding errors:", response_text) | |
| # Return response in the thread | |
| say( | |
| # text=f"Oh hi <@{user_id}>!\n\n{response_text}", | |
| text=f"{response_text}", | |
| thread_ts=thread_ts, | |
| ) |
Lets look at how we actually get that response. First, we check if we’ve enabled guardrails. Guardrails are an AI policing system at AWS Bedrock, and can police content in or out of the models, but has to be enabled and you’ll send different payloads based on whether that flag is enabled.
There’s probably a smarter way to include/exclude some payload keys, but I’m a python n00b and don’t know how. Please, someone educate me if there’s a better way than this.
On line 5, we invoke our bedrock model, and pass forward a bunch of the constants we set above, like our model, guardrail information, as well as the anthropic version line 11), and a max token value (line 13).
1024 tokens is a good chunk, and I haven’t hit this limit yet, even with complex image processing or long slack threads. I imagine we’ll bump this up as our use cases get more complex. Note that Bedrock charges based on tokens consumed, so upping this number potentially increases your bills.
On line 14, we pass forward the (potentially HUGE) map of messages we have carefully constructed from the slack message, thread content, and any files included from anyone in the thread.
On line 15 and 16, we include the temperature and system model guidance.
Line 21+ is just if we don’t have guardrails enabled, and is exactly the same otherwise but excludes the top-level keys related to guardrails.
| # Function to handle ai request input and response | |
| def ai_request(bedrock_client, messages): | |
| # If enable_guardrails is set to True, include guardrailIdentifier and guardrailVersion in the request | |
| if enable_guardrails: | |
| response = bedrock_client.invoke_model( | |
| modelId=model_id, | |
| guardrailIdentifier=guardrailIdentifier, | |
| guardrailVersion=guardrailVersion, | |
| body=json.dumps( | |
| { | |
| "anthropic_version": anthropic_version, | |
| # "betas": ["pdfs-2024-09-25"], # This is not yet supported, https://docs.anthropic.com/en/docs/build-with-claude/pdf-support#supported-platforms-and-models | |
| "max_tokens": 1024, | |
| "messages": messages, | |
| "temperature": temperature, | |
| "system": model_guidance, | |
| } | |
| ), | |
| ) | |
| # If enable_guardrails is set to False, do not include guardrailIdentifier and guardrailVersion in the request | |
| else: | |
| response = bedrock_client.invoke_model( | |
| modelId=model_id, | |
| body=json.dumps( | |
| { | |
| "anthropic_version": anthropic_version, | |
| # "betas": ["pdfs-2024-09-25"], # This is not yet supported, https://docs.anthropic.com/en/docs/build-with-claude/pdf-support#supported-platforms-and-models | |
| "max_tokens": 1024, | |
| "messages": messages, | |
| "temperature": temperature, | |
| "system": model_guidance, | |
| } | |
| ), | |
| ) | |
| return response |
Next up, in our main function, we start our app in local mode, which means run listening on a local port.
We can run the app in Websocket mode, which obviates the need for grok, but we want to make this app easily mappable to lambda, which will receive 1 webhook payload at a time, rather than running all the time in webhook mode, so running as an app with a local listener like this helps us make sense of how that mapping works. More in the next article.
| # Main function | |
| if __name__ == "__main__": | |
| ... | |
| # Start the app in websocket mode for local development | |
| # Will require a separate terminal to run ngrok, e.g.: ngrok http http://localhost:3000 | |
| print("🚀 Starting the app") | |
| app.start( | |
| port=int(os.environ.get("PORT", 3000)), | |
| ) |
Run the App
If you’ve cloned down the repo, you can now attempt to run the app. If it all works, it’ll look like this:
> python3 lambda/src/devopsbot.py 🚀 Local server starting starting 🚀 Successfully got secret DEVOPSBOT_SECRETS_JSON from AWS Secrets Manager 🚀 Registering the Slack handler 🚀 Registering the AWS Bedrock client 🚀 Starting the app ⚡️ Bolt app is running! (development server)If it logs an error about fetching secrets, make sure you’ve exported AWS credentials into your terminal. Also note if you’re using ephemeral logins (like the AWS SSO page), they’ll expire every few hours and you’ll need to fetch new ones.
export AWS_ACCESS_KEY_ID="ASI….HE" export AWS_SECRET_ACCESS_KEY="4p…sb" export AWS_SESSION_TOKEN="IQ…To"If your terminal complains about dependencies, you can create a virtual environment and install the dependencies with this snipped. Make sure you have python 3.12 installed with “python3.12 --version”.
# Create new python 3.12 venv python3.12 -m venv . # Activate the venv source ./bin/activate # Install dependencies python3 -m pip install --upgrade pip python3 -m pip install boto3 python3 -m pip install slack_bolt python3 -m pip install requestsGrok it to Receive Public Slack Webhooks
Of course, this is now only running with a local listener port, not one exposed to the internet. That’s not great - it won’t be reachable from Slack’s public API servers that’ll generate these webhooks.
So we need to turn on an ngrok instance!
If you don’t have ngrok installed, you can download it here.
Once you have it installed, start ngrok with a command like the following. That’ll pipe a public ngrok http listener to your localhost on port 3000, which we told our slack bolt server to listen on.
ngrok http http://localhost:3000The output of ngrok will look like this:
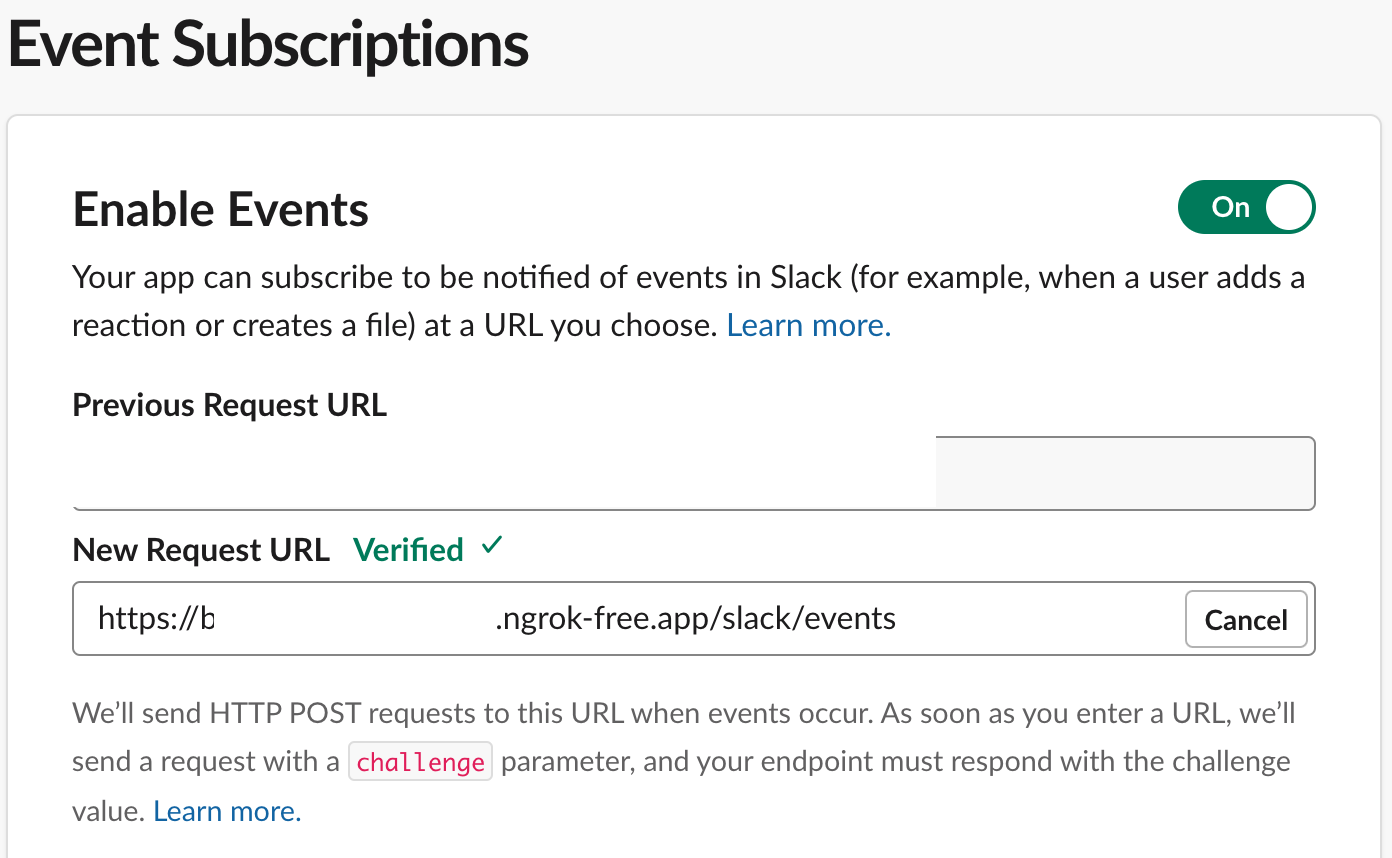
Session Status online Account Kyler Middleton (Plan: Free) Version 3.19.0 Region United States (us) Latency 27ms Web Interface http://127.0.0.1:4040 Forwarding https://abcd-76-255-29-157.ngrok-free.app -> http://localhost:3000 Connections ttl opn rt1 rt5 p50 p90 0 0 0.00 0.00 0.00 0.00See the line that says “forwarding”. This is a public http listener, copy that to your clipboard, and lets go back to our Slack App configuration page on Features —> Event Subscriptions. We need to tell our slack app what our ngrok public endpoint is.
Paste your ngrok url into the new request URL page. You’ll probably see an error like this, which means our URL isn’t quite right. Interestingly, the Slack Bolt listener doesn’t listen on the root URL, instead it listens on (url)/slack/events.

So lets update our ngrok string to have /slack/events on the end. If you see “Verified” above your URL, then the public Slack servers sent a challenge request to your endpoint, and your endpoint responded correctly.
WOOT
Remember to click save to update our Slack app to use your ngrok webhook.
Test It!
With our Ngrok running, our Slack app pointed to it for webhooks, and with our local python relay running and listening on localhost:3000, lets head over to slack to really test the thing.
You can either DM your Slack App, or you can go to a shared room and tag the app with a message.
Vera will always respond in a thread to keep her sanity, in a pretty literal way. In local mode, if we didn’t respond in a thread, and retained a history of all previous messages in a DM flow, then when you change topics, Vera might get confused. Imagine all the conversations everyone has had with you the past week in your head at the same time when someone asks an unrelated question.
Prioritize AI sanity, value Slack thread context boundaries.

Regardless of whether it works or not, you should see logs in your python terminal. If you’ve exported VERA_DEBUG=True, then Vera will print A LOT of information, like the state of the conversation content blocks on every update, which can be a lot.
Here’s what it can look like:
> python3 lambda/src/devopsbot.py ... 127.0.0.1 - - [27/Dec/2024 14:40:23] "POST /slack/events HTTP/1.1" 200 - 🚀 Headers: {'host': ['bfxxxxx.ngrok-free.app'], 'user-agent': ['Slackbot 1.0 (+https://api.slack.com/robots)'], 'content-length': ['897'], 'accept': ['*/*'], 'accept-encoding': ['gzip,deflate'], 'content-type': ['application/json'], 'x-forwarded-for': ['1.2.3.4'], 'x-forwarded-host': ['bfxxxx7.ngrok-free.app'], 'x-forwarded-proto': ['https'], 'x-slack-request-timestamp': ['1735332212'], 'x-slack-signature': ['v0=41ac0bd6e123dc117f7e5e119016dc903bfb47d40ee225e9b792e292bbe7f573']} 🚀 Payload: {'user': 'xxxxxx', 'type': 'message', 'ts': '1735332212.219499', 'client_msg_id': 'ab9c3403-297f-4239-80bb-0734ffa0f563', 'text': 'Hey Vera, you up?', 'team': 'TA01ELZ5M', 'blocks': [{'type': 'rich_text', 'block_id': '/BhvB', 'elements': [{'type': 'rich_text_section', 'elements': [{'type': 'text', 'text': 'Hey Vera, you up?'}]}]}], 'channel': 'D081EH5RUM9', 'event_ts': '1735332212.219499', 'channel_type': 'im'} 🚀 Text found in payload: Hey Vera, you up? 🚀 User conversation content: [{'type': 'text', 'text': 'Kyler Middleton says: Hey Vera, you up?'}] 🚀 State of conversation after append user's prompt: [{'role': 'user', 'content': [{'type': 'text', 'text': 'Kyler Middleton says: Hey Vera, you up?'}]}] 🚀 State of conversation before check if convo is empty: [{'role': 'user', 'content': [{'type': 'text', 'text': 'Kyler Middleton says: Hey Vera, you up?'}]}] 🚀 State of conversation before AI request: [{'role': 'user', 'content': [{'type': 'text', 'text': 'Kyler Middleton says: Hey Vera, you up?'}]}] 🚀 Response body: {"id":"msg_bdrk_01DWabTNqEkkes9ab1UVsUAd","type":"message","role":"assistant","model":"claude-3-5-sonnet-20241022","content":[{"type":"text","text":"Hi Kyler! Yes, I'm up and ready to help! What can I assist you with today?"}],"stop_reason":"end_turn","stop_sequence":null,"usage":{"input_tokens":411,"output_tokens":26},"amazon-bedrock-guardrailAction":"NONE"} 🚀 response_json['content']: [{'type': 'text', 'text': "Hi Kyler! Yes, I'm up and ready to help! What can I assist you with today?"}] 🚀 response_text: Hi Kyler! Yes, I'm up and ready to help! What can I assist you with today?If it doesn’t work, read through the error messages.
Summary
This article got HUGE (4.5k words!!). In it, we walked through the entire implementation of our Slack App and Bedrock AI relay.
We talked about how we use Slack Threads as conversation context borders and why (read: AI sanity).
We talked about how Slack will send us webhooks for all sorts of relevant stuff (and some stuff we don’t care about), and how we filter the messages we don’t care about.
We talked about the current limitations of this slack bot, namely that it can only support a half dozen image file formats, and doesn’t yet support PDF, Doc, Excel, etc. Hopefully these will be supported soon, and I’m considering rewriting the whole shebang in the .converse() API format so it can support those out of the box. We’ll see when we get there.
The last article in this series is how to convert all of this to an AWS Lambda so we can run it in serverless mode and won’t require our local server to run. I also don’t want to deploy a VM anywhere and need to patch and maintain the thing with downtime.
Serverless means it’ll just… work. Like, forever, and I can kick my feet up. #HeavilyEngineeredLaziness
Heavily Engineered Laziness is an excellent alternate name for this blog.
Hope this helps ya! Good luck out there.
kyler