
🔥Let’s Do DevOps: CloudFront Lambda@Edge to Add CSP HTTP Headers
This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can…

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
S3 is great for storing files, and CloudFront is great for global content delivery caching and speed. You can set up an incredible website with these two resources. However, your security team will soon ask you to add some Content Security Policy (CSP) HTTP headers to the traffic, and you’ll need to tell them that CloudFront doesn’t support that yet.
Note: CloudFront DOES now support CSP headers! And even arbitrary headers, which is awesome and easier than this method. You can use this article for other lambda@edge use cases, and the new article for how to do CSP headers at CloudFront layer.
Lambda@Edge integrates with CloudFront and can manipulate traffic in flight in a variety of ways, which can do some incredible things. In this blog we’ll shim in some HTTP headers from source S3 → CloudFront on the back-side of our CloudFront cache. This means the Lambda will only run when the cache is cleared and the S3 origin content is fetched (read: not very often), but we still get CSP header security.
Let’s do it!
Code will be boxed in and discussed inline, and all code will be runnable and linked to github repos at the end of this article.
Definitions
Before we dive into theory, let’s do some definitions to get us started.
S3 Bucket — AWS service to store files. Integrated with by many services
Lambda — AWS serverless service, able to run code when triggered. Also integrated with by many services
CloudFront — AWS Content Delivery Network (CDN), caches and distributes files to many points across the Earth for quick access from almost anywhere
CloudFront Origin — The Origin is where CloudFront is pulling files from. It needs an origin so it can cache the content and distribute it.
Caching — Caching is the concept of polling data from somewhere and storing it. CloudFront does this by pulling data from your Origin (probably S3) and storing it within the CloudFront nodes all over the world to decrease user latency when accessing your stuff!
IAM — Identity and Access Management (IAM) policies control what each principal (user, role, AWS service) is permitted to do
Lambda@Edge Theory
Lambdas are a method to run code without providing any servers. They’re great for very quick atomic operations. The Lambda service supports any number of triggers which permit us to run our lambda and have it do stuff. That stuff is up to you, since it’s your code that’s running!
Lambda@Edge is the concept of integrating Lambda deeply into CloudFront’s cache. It permits Lambdas to be run in 4 different specific circumstances:
Viewer Request — The public side request coming into Cloudfront is called the “viewer”, and we can modify the request before it’s processed by CloudFront
Viewer Response — Modify the data sent back to the viewer
afterthe request is processed by CloudFrontOrigin Request — Modify the cache refresh message sent to the Origin, which is usually an S3 bucket
Origin Response — Modify the data sent from the Origin
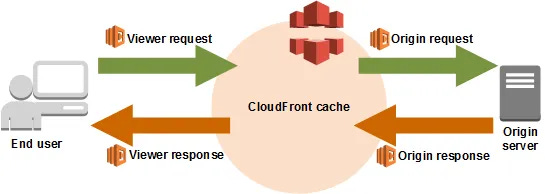
Now, in our use case, we want to modify the data provided to our users, which means we can either modify Origin response or Viewer response. Either would work perfectly, right? We can shim headers in at either place and the user would see them.
If we use Viewer response, the lambda would run each time the CloudFront is accessed, which could be… a lot! And that might be expensive, and would add a little latency to the end user’s request to us.
If we use Origin response, the lambda would run only each time CloudFront dumped its cache and renewed the data from our Origin. That’s pretty rarely, and has the same benefits — the headers would be cached by CloudFront, so same outcome. And this one saves us $$! Let’s use this one.
Hosting a Website in S3
First of all, let’s build our S3 bucket and put our website on it. Our site will be a single index.html page for this demo. In the real world, sites are tested and deployed via content management tools because there many be thousands or millions of pages to host.
We create a locals file with our S3 bucket name because we’ll be referencing it a few times, and then we create our S3 bucket. In previous iterations of the AWS terraform provider, the S3 bucket resource was a monolith and had a ton of configuration in it. In the new versions, each configuration block for S3 is a separate resource. We’ll go over that shortly.
We also set our S3 bucket to use the private ACL, which means access isn’t permitted except where our policy permits it.
| locals { | |
| s3_bucket_name = "kyler-s3-bucket-asdfas" | |
| } | |
| resource "aws_s3_bucket" "s3_bucket" { | |
| bucket = local.s3_bucket_name | |
| tags = { | |
| Name = local.s3_bucket_name | |
| } | |
| } | |
| resource "aws_s3_bucket_acl" "s3_bucket_acl" { | |
| bucket = aws_s3_bucket.s3_bucket.id | |
| acl = "private" | |
| } |
Next we create an S3 bucket policy to permit only cloudfront and assign it to our bucket. Our goal is that folks can’t bypass our security layer (CloudFront) and access our files directly in the S3 bucket.
| resource "aws_s3_bucket_policy" "s3_bucket_policy" { | |
| bucket = aws_s3_bucket.s3_bucket.id | |
| policy = data.aws_iam_policy_document.cloudfront_access.json | |
| } | |
| data "aws_iam_policy_document" "cloudfront_access" { | |
| statement { | |
| sid = "PermitCloudfrontOnly" | |
| principals { | |
| type = "AWS" | |
| identifiers = [ | |
| aws_cloudfront_origin_access_identity.origin_access_identity.iam_arn | |
| ] | |
| } | |
| actions = [ | |
| "s3:GetObject", | |
| ] | |
| resources = [ | |
| "arn:aws:s3:::${local.s3_bucket_name}/*", | |
| ] | |
| } | |
| } |
We create a flat index.html page to represent our website.
| <HTML> | |
| <HEAD> | |
| <TITLE>Website for testing CloudFront Lambda</TITLE> | |
| </HEAD> | |
| <BODY BGCOLOR="FFFFFF"> | |
| <HR> | |
| <H1>Congratulations!</H1> | |
| Your website appears to be working!! <BR> | |
| <HR> | |
| </BODY> | |
| </HTML> |
We have Terraform grab that index.html file and upload it to the S3 bucket. The etag attribute acts as a trigger, and will cause the file to be re-uploaded to the bucket if its md5 hash changes in any way.
| resource "aws_s3_object" "website" { | |
| bucket = aws_s3_bucket.s3_bucket.id | |
| key = "index.html" | |
| acl = "private" | |
| source = "index.html" | |
| etag = filemd5("index.html") | |
| content_type = "text/html" | |
| } |
We tell the S3 bucket to act as a web server:
| resource "aws_s3_bucket_website_configuration" "web_hosting" { | |
| bucket = aws_s3_bucket.s3_bucket.id | |
| index_document { | |
| suffix = "index.html" | |
| } | |
| } |
And then we tell terraform to invalidate our CloudFront cache each time this file is updated. That means if we modify our index.html file, then run terraform, it’ll:
Update the S3 bucket with our new file
Tell CloudFront to invalidate it’s cache, which triggers CloudFront to fetch the new version and start serving it. All in < 30 seconds!
| resource "null_resource" "invalidate_cf_cache" { | |
| provisioner "local-exec" { | |
| command = "aws cloudfront create-invalidation --distribution-id ${aws_cloudfront_distribution.s3_distribution.id} --paths '/*'" | |
| } | |
| triggers = { | |
| website_version_changed = aws_s3_object.website.version_id | |
| } | |
| } |
Building a Lambda To Modify HTTP Headers
Next we need to write a lambda to shim in HTTP headers. We’ll use NodeJS. Let’s start with our lambda.js file. See how each header from line 9–15 is a separate line, and can be updated to enforce HTTP security policy. Save this in the same directory where your TF lives.
| 'use strict'; | |
| exports.handler = (event, context, callback) => { | |
| //Get contents of response | |
| const response = event.Records[0].cf.response; | |
| const headers = response.headers; | |
| //Set new headers | |
| headers['strict-transport-security'] = [{key: 'Strict-Transport-Security', value: 'max-age=63072000; includeSubdomains; preload'}]; | |
| headers['content-security-policy'] = [{key: 'Content-Security-Policy', value: "default-src 'self' *.domain1.com *.domain2.com; font-src 'self' fonts.gstatic.com; frame-src *.domain1.com *.domain2.net; img-src 'self' data: *.domain1.com *.domain2.com; object-src 'none'; script-src 'self' 'unsafe-inline' 'unsafe-eval' *.domain1.com *.domain2.com; style-src 'self' 'unsafe-inline' *.domain1.com *.domain2.com;"}]; | |
| headers['x-content-type-options'] = [{key: 'X-Content-Type-Options', value: 'nosniff'}]; | |
| headers['x-frame-options'] = [{key: 'X-Frame-Options', value: 'DENY'}]; | |
| headers['x-xss-protection'] = [{key: 'X-XSS-Protection', value: '1; mode=block'}]; | |
| headers['referrer-policy'] = [{key: 'Referrer-Policy', value: 'same-origin'}]; | |
| headers['Cache-Control'] = [{key: 'Cache-Control', value: 'max-age=31536000'}] | |
| //Return modified response | |
| callback(null, response); | |
| }; |
Lambda requires our code to be zipped up, so first let’s zip up our lambda.js file into a .zip file on line 2.
Then on line 8 we create our lambda. There are a few interesting things here. Line 9 must match the name of our zip file. Line 11 is our Lambda IAM role, which we’ll cover next.
Line 12 is our handler, which was a new concept to me before this project. It’s basically our code ingress point, in case your NodeJS code contains multiple functions you might want to start with. If you don’t have a function name (like we don’t), the handler should be (file_name).handler. So in our case, lambda.handler.
Line 15, publish, must be true. CloudFront can’t access Lambda versions unless they are published. Line 18 is checking the base64sha256 hash of our file to see if it’s changed, and if yes, it’ll publish a new version of the lambda. And line 20 is our runtime, the specific version of NodeJS we want to run our code.
| # Zip up lambda when it changes | |
| data "archive_file" "lambda" { | |
| type = "zip" | |
| source_file = "lambda.js" | |
| output_path = "lambda.zip" | |
| } | |
| resource "aws_lambda_function" "lambda_function" { | |
| filename = "lambda.zip" | |
| function_name = "HttpHeaderShim" | |
| role = aws_iam_role.lambda_role.arn | |
| handler = "lambda.handler" | |
| # Publishes new versions on source update, required for Lambda@Edge with CloudFront | |
| publish = true | |
| # Hash the source file, if it changes, lambda will be updated | |
| source_code_hash = data.archive_file.lambda.output_base64sha256 | |
| runtime = "nodejs12.x" | |
| } |
We want CloudFront to be able to trigger our Lambda when it calls it, and the service Amazon named it is edgelambda, so we add that to the AWS Services which are able to assume this role and do things.
| resource "aws_iam_role" "lambda_role" { | |
| name = "HttpHeaderShimLambdaRole" | |
| assume_role_policy = jsonencode({ | |
| Version = "2012-10-17" | |
| Statement = [ | |
| { | |
| Action = "sts:AssumeRole" | |
| Effect = "Allow" | |
| Sid = "" | |
| Principal = { | |
| Service = [ | |
| "lambda.amazonaws.com", | |
| "edgelambda.amazonaws.com", | |
| ] | |
| } | |
| } | |
| ] | |
| }) | |
| } |
Then we create our permissions policy for lambda, which permits our lambda to write logs when its’ run, which is great for troubleshooting. Then we link the two together.
| resource "aws_iam_policy" "lambda_policy" { | |
| name = "HttpHeaderShimLambdaPolicy" | |
| description = "Http Header Shim Lambda Policy" | |
| policy = jsonencode({ | |
| "Version" : "2012-10-17", | |
| "Statement" : [ | |
| { | |
| "Action" : [ | |
| "cloudwatch:PutMetricData", | |
| "logs:CreateLogGroup", | |
| "logs:CreateLogStream", | |
| "logs:PutLogEvents" | |
| ], | |
| "Resource" : [ | |
| "*" | |
| ], | |
| "Effect" : "Allow", | |
| "Sid" : "CloudWatchPutMetricData" | |
| } | |
| ] | |
| }) | |
| } | |
| resource "aws_iam_role_policy_attachment" "lambda-policy" { | |
| role = aws_iam_role.lambda_role.name | |
| policy_arn = aws_iam_policy.lambda_policy.arn | |
| } |
CloudFront with Lambda@Edge and Caching
Now for the good stuff, let’s build some CloudFront, tell it to source all files from our S3 bucket, and integrate it with our fancy lambda.
Origin ID is an local mapping name for where we’ll grab our files from. We’ll reference it a few times, so we set up a local name for it.
Then we build a Cloudfront Access Identity — you’ll see this called an OAI all over AWS. It does nothing as far as I can tell but we have to build it ¯\_(ツ)_/¯
| locals { | |
| s3_origin_id = "S3OriginId" | |
| } | |
| resource "aws_cloudfront_origin_access_identity" "origin_access_identity" { | |
| comment = "CF Origin Access Identity" | |
| } |
There’s a lot going on here, so let’s walk through it piece by piece.
Line 1 — we use a data call to find the CachingOptimized cache policy ID. We’ll use that attribute in our policy, and it gets a dynamic name per account.
Line 6 — We set the origin for our CloudFront to our S3 bucket.
Line 18 — The default root object of our CloudFront is the index.html, which means if anyone goes directly to our cloudfront distribution they’ll be served the index.html page.
Line 20 — Defines the default cache behavior, which is to cache GET, HEAD (line 22), pull files from the S3 origin (line 23), compress everything for storage in CloudFront (line 24), use our caching policy we looked up on line 1 (line 25).
Line 32 is where we associate our lambda and call out “origin-response” lambda@Edge type.
Line 47 says to use a default https cert, which is perfect for a lab (but probably not what you want in your enterprise!).
| data "aws_cloudfront_cache_policy" "caching_optimized" { | |
| name = "Managed-CachingOptimized" | |
| } | |
| resource "aws_cloudfront_distribution" "s3_distribution" { | |
| origin { | |
| domain_name = aws_s3_bucket.s3_bucket.bucket_regional_domain_name | |
| origin_id = local.s3_origin_id | |
| s3_origin_config { | |
| origin_access_identity = aws_cloudfront_origin_access_identity.origin_access_identity.cloudfront_access_identity_path | |
| } | |
| } | |
| enabled = true | |
| is_ipv6_enabled = false | |
| comment = "S3 CloudFront" | |
| default_root_object = "index.html" | |
| default_cache_behavior { | |
| allowed_methods = ["DELETE", "GET", "HEAD", "OPTIONS", "PATCH", "POST", "PUT"] | |
| cached_methods = ["GET", "HEAD"] | |
| target_origin_id = local.s3_origin_id | |
| compress = true | |
| cache_policy_id = data.aws_cloudfront_cache_policy.caching_optimized.id | |
| viewer_protocol_policy = "allow-all" | |
| # For default responses (not http-->https redirect), trigger lambda on response from origin | |
| # Could also modify on viewer response, but origin-response will cache headers and limit lambda run volume | |
| lambda_function_association { | |
| event_type = "origin-response" | |
| lambda_arn = aws_lambda_function.lambda_function.qualified_arn | |
| } | |
| } | |
| price_class = "PriceClass_200" | |
| restrictions { | |
| geo_restriction { | |
| restriction_type = "whitelist" | |
| locations = ["US"] | |
| } | |
| } | |
| viewer_certificate { | |
| cloudfront_default_certificate = true | |
| } | |
| } |
And then we output the cloudfront distribution’s name along with some http stuff so it’s a clickable link.
| output "site_can_be_reached_at" { | |
| value = "https://${aws_cloudfront_distribution.s3_distribution.domain_name}/" | |
| } |
Test It Out!
After we run terraform and it builds all the things, we can curl to the cloudfront distribution to test if the new headers exist, and boom, there we are! Line 3–8 are our headers, injected by NodeJS and cached in CloudFront before being sent to our client. Amazing.
| curl -vvv https://xxxxxxxx.cloudfront.net/ 2>&1 | |
| (removed) | |
| < strict-transport-security: max-age=63072000; includeSubdomains; preload | |
| < content-security-policy: default-src 'self' *.domain1.com *.domain2.com; font-src 'self' fonts.gstatic.com; frame-src *.domain1.com *.domain2.net; img-src 'self' data: *.domain1.com *.domain2.com; object-src 'none'; script-src 'self' 'unsafe-inline' 'unsafe-eval' *.domain1.com *.domain2.com; style-src 'self' 'unsafe-inline' *.domain1.com *.domain2.com; | |
| < x-content-type-options: nosniff | |
| < x-frame-options: DENY | |
| < x-xss-protection: 1; mode=block | |
| < referrer-policy: same-origin | |
| (removed) | |
| <HTML> | |
| <HEAD> | |
| <TITLE>Website for testing CloudFront Lambda</TITLE> | |
| </HEAD> | |
| <BODY BGCOLOR="FFFFFF"> | |
| <HR> | |
| <H1>Congratulations!</H1> | |
| Your website appears to be working!! <BR> | |
| <HR> | |
| </BODY> | |
| </HTML> |
Summary
We covered Lambda@Edge architecture principals, then built an S3 bucket with a policy to permit only CloudFront, a lambda in NodeJS to shim CORS HTTP headers in, and a CloudFront distribution, then linked CloudFront to the Lambda using Lambda@Edge.
Then we used curl to confirm that all our headers are shimmed in and cached. And we’re off to the races!
In an upcoming article I’ll deploy the new CloudFront header shim configuration that no longer utilizes lambda. Until then,
Good luck out there!
kyler