
🔥Let’s Do DevOps: GitHub API Paginated Calls (More than 1K Repos!)
This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can…

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
I previously wrote a story about setting permissions and branch protections on hundreds of repos. That tool works fantastically, and is a standard at my work. However, we have now crossed over 1k repos!
Which is amazing, but also caused the tool I wrote to no longer get all of them. As I came to find out, the gh cli tool I used to get all the repo names uses the GitHub Search API, which is limited to 1k results, and isn’t paginated. That means you simply can’t get more repos using it (without tricks like calling repos since a certain date, which isn’t very reliable).
This snuck up on us — when I wrote the tool, we had fewer than 1k repos, so I saw no error messages, and the number of repos the gh repo list command printed matched the number we had! It was only through examining the logs after we passed 1k repos that I saw we were only getting the first 1k of them.
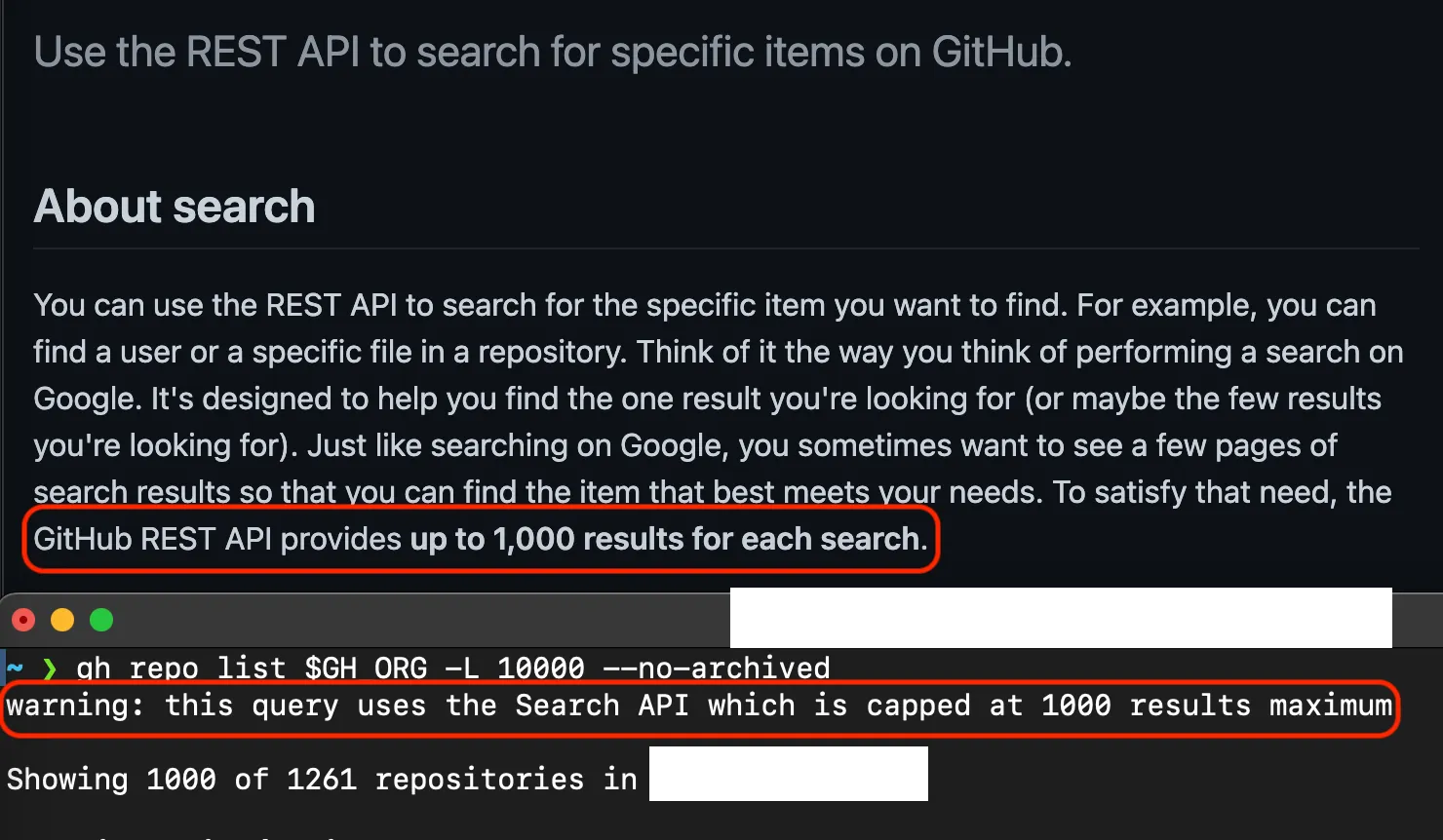
I rewrote the Action to use the REST API, which only provides 100 repos at a time, but is paginated, so you can simply keep calling the API until all repos are returned. Let’s walk through how I implemented a paginated API call in bash for a GitHub Action to get more than 1k repos in our GitHub Org!
How Many Repos Do I Have?
It’s harder than it seems to find out exactly how many repos you have in your GitHub Org once you have more than 1k. Below that number, you can see the exact count in the GitHub.com UI on the Repositories tab.
But after you have more than 1k, the repository number is rounded. That makes it hard to double-check our automation and make sure we are finding all of them!
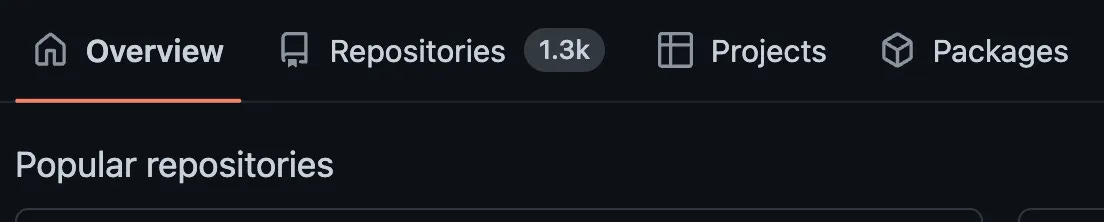
We could use the output from the gh repo list command, but it’s just bitten me with a limitation — plus, I don’t want to rely on an informational output from the gh cli that might change at any time. Rather, let’s try and find that information from a more reliable data source — the Org Info REST API!
It provides information on the Organization itself, including 2 values we can use to find out total repo count — public_repos + owned_private_repos.
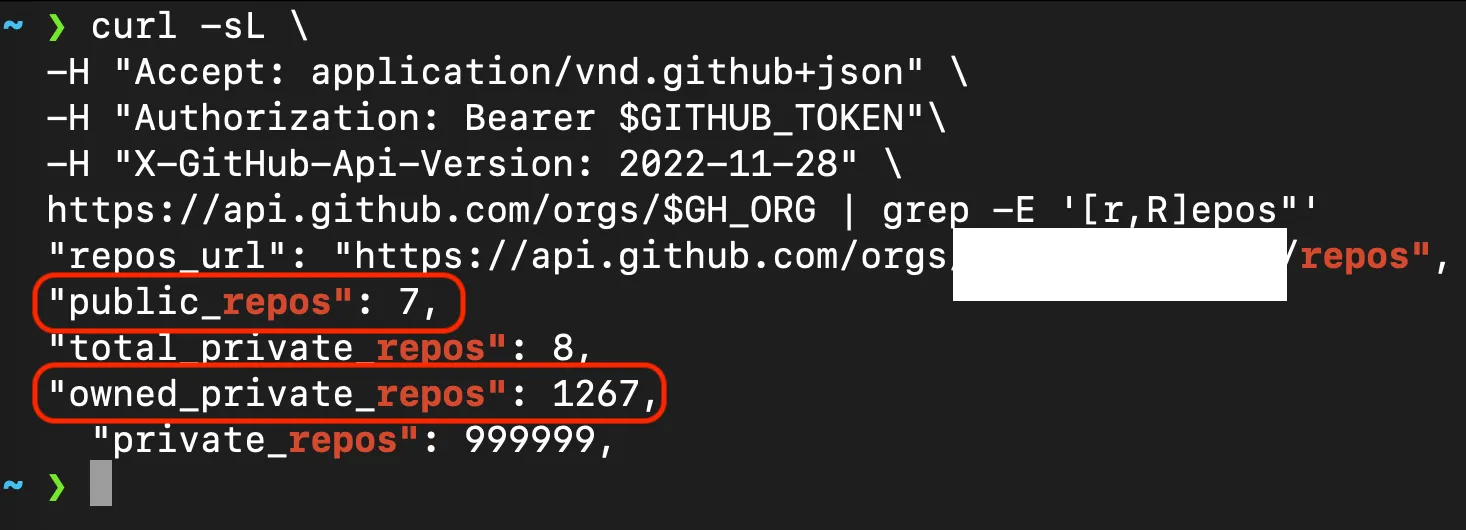
So let’s call that information — rather than calling it twice, let’s write it to a file (line 5). Then we can set a few values — the private repo count (line 8) and the public repo count (line 9). Then our total repos in our org (line 10) is just simple math.
| curl -sL \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN"\ | |
| -H "X-GitHub-Api-Version: 2022-11-28" \ | |
| https://api.github.com/orgs/$GH_ORG > org_info.json | |
| # Filter org info to get repo counts | |
| PRIVATE_REPO_COUNT=$(cat org_info.json | jq -r '.owned_private_repos') | |
| PUBLIC_REPO_COUNT=$(cat org_info.json | jq -r '.public_repos') | |
| TOTAL_REPO_COUNT=$(($PRIVATE_REPO_COUNT + $PUBLIC_REPO_COUNT)) |
Paginated Calls — How Many Times?
Okay, we know how many repos we have. How many times do we have to call the REST API endpoint for repo information until we’re done? Well, we don’t know yet. Let’s check how many repos we’re allowed to get at a time.
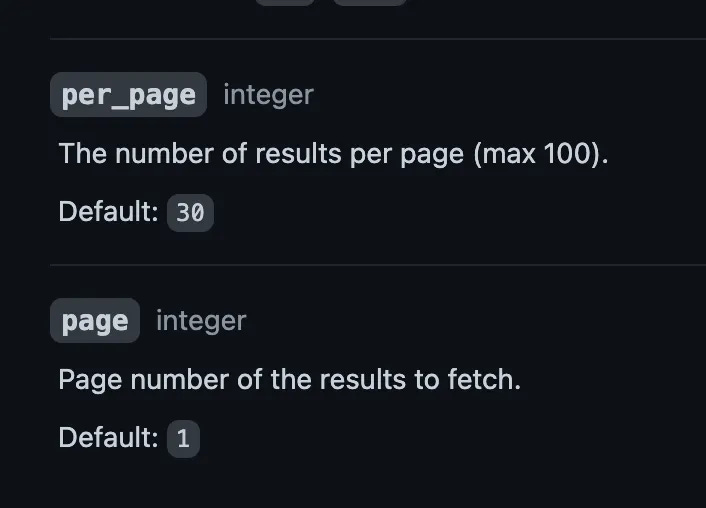
According to the List Organization Repositories REST call, we can set two arguments in the API call that are useful here — first, we can say that for each page, we want 100 repos. That’s the max it will permit, so let’s do it. Second, we can set which page we want. So we can iterate on that.
Now we need to figure out how many times we’ll call the API. We have 1,274 repos, and we can call 100 repos at a time. For a human, that math isn’t too hard — we should call it 13 times, right? For a computer, it takes a little doing. Thanks to GitHub CoPilot, this was a tab away. We set how many repos we can call at a time (line 2) and then we divide our total by the number we can call at a time (line 3). That’s 12.74 times, and since we’re storing this value as a (non-floating) int, we round down to 12.
Then on line 4 we check if there’s a remainder. If there’s any remainder at all, we add 1 to the value, to call the API once more. Pretty neat trick, and written entirely by AI. All hail our new overloads and whatnot.
| # Calculate number of pages needed to get all repos | |
| REPOS_PER_PAGE=100 | |
| PAGES_NEEDED=$(($TOTAL_REPO_COUNT / $REPOS_PER_PAGE)) | |
| if [ $(($TOTAL_REPO_COUNT % $REPOS_PER_PAGE)) -gt 0 ]; then | |
| PAGES_NEEDED=$(($PAGES_NEEDED + 1)) | |
| fi |
Go Get the Repos, and build our Repo List
Now we know how many times to call the API, so let’s do it. We do a simple for loop, which we can tell to run n number of times with the seq command. seq is a neat tool, here we’re saying seq 13 and it prints out 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 , and the for loop sets PAGE_NUMBER to that value on each iteration.
We then call ALL the repo information (which is a lot!), and on line 9 we do some cool things — we say we want 100 repos per page, we want them sorted by “pushed” (to match the github.com UI), and we use jq to just spit out the names of the repos, and not any other info.
Note here, it’d likely be way faster to use GraphQL for this info — you could tell graphql to only send us the names, rather than it sending us ALL the info and then us immediately throwing most of it away. I’ll update this at some point to use graphql instead to shave off some seconds, but it works for now.
Then on line 13 we concat our bucket for repo names, ALL_REPOS, with our new batch of repo names, PAGINATED_REPOS. Note the \n between them. I left this off at first and it was combining lines. The \n tells the loop to append a return on the last item in the ALL_REPOS list before adding the new stuff, so everyone gets their own line.
| for PAGE_NUMBER in $(seq $PAGES_NEEDED); do | |
| echo "Getting repos page $PAGE_NUMBER of $PAGES_NEEDED" | |
| # Could replace this with graphql call (would likely be faster, more efficient), but this works for now | |
| PAGINATED_REPOS=$(curl -sL \ | |
| -H "Accept: application/vnd.github+json" \ | |
| -H "Authorization: Bearer $GITHUB_TOKEN"\ | |
| -H "X-GitHub-Api-Version: 2022-11-28" \ | |
| "https://api.github.com/orgs/$GH_ORG/repos?per_page=$REPOS_PER_PAGE&sort=pushed&page=$PAGE_NUMBER" | jq -r '.[].name') | |
| # Combine all pages of repos into one variable | |
| # Extra return added since last item in list doesn't have newline (would otherwise combine two repos on one line) | |
| ALL_REPOS="${ALL_REPOS}"$'\n'"${PAGINATED_REPOS}" | |
| done |
And remember in our old way, we were using gh repo list with the no-archive flag. I don’t want to include archived repos — they are locked, which means there’s no reason to try and set their settings and permissions — all modification operations would fail anyway.
So let’s find out which repos on our list are the archived ones with our trusty gh repo list command, but now we ONLY want the archived repos --archived, and we use cut to just get the repo names.
Then on line 6 we loop through each archived repo name, and do a cool trick with grep. Grep is a magical, wonderful CLI tool used for searching text for matches. We’re using it in -v mode, which is Invert Match. That means to return all the lines that DON’T match.
So on line 7 we’re saying set ALL_REPOS to the value of ALL_REPOS, but don’t include any line that matches an archived repo name. We even include a ^ (beginning of line) and $(end of line) to make sure there’s no substring matches happening (like “repo” matching “repo5” and “repo_list”). ✨Grep is magical ✨
| # Find archived repos | |
| ARCHIVED_REPOS=$(gh repo list $GH_ORG -L 1000 --archived | cut -d "/" -f 2 | cut -f 1) | |
| # Remove archived repos from ALL_REPOS | |
| echo "Removing archived repos, they are read only" | |
| for repo in $ARCHIVED_REPOS; do | |
| ALL_REPOS=$(echo "$ALL_REPOS" | grep -vE "^$repo$") | |
| done |
Then some housekeeping — this method creates some blank lines — probably only 1 at the very beginning of our list, but in case there’s others, let’s remove them with awk 'NF.
And let’s track how many repos there are by doing a line count with wc -l, and stripping any extra spaces off that number with xargs.
| # Remove any empty lines | |
| ALL_REPOS=$(echo "$ALL_REPOS" | awk 'NF') | |
| # Get repo count | |
| ALL_REPOS_COUNT=$(echo "$ALL_REPOS" | wc -l | xargs) |
Summary
In this article, we converted our tool from using a tool that was limited to 1k responses to a paginated API that’s capable of pulling an unlimited number of repos. We combined all the repos together, and then removed the repo types we didn’t want to include (“archived” repos).
Then we cleaned up our data and counted our repos.
This same pattern would work to convert from a single call to a paginated call for lots of different use cases. I hope it helps!
Good luck out there.
kyler