
🔥Let’s Do DevOps: Share ECR Docker Image and Secrets Between AWS Accounts

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
Hey all!
As we’ve scaled out our CI/CD (~175 pipelines across 75 accounts) to have many builders (~25 pools, ~50 or so builders), we’ve seen pain points where the way we were doing it before just wasn’t cutting it. I’ve written extensively about how graphical, manually-managed pipelines just couldn’t scale beyond about 50 — I’d spend literally all day every day just updating Terraform versions, and double-checking store accounts, and no one wants that job.
We eventually wrote out our pipelines in YAML, and now manage them via pull requests in a git repo. That permits variables (to conclusively match storage accounts and account IDs among steps in a pipeline), and also mass updates — find/replace for terraform versions. That has been a roaring success, and we’ve adopted that model all over.
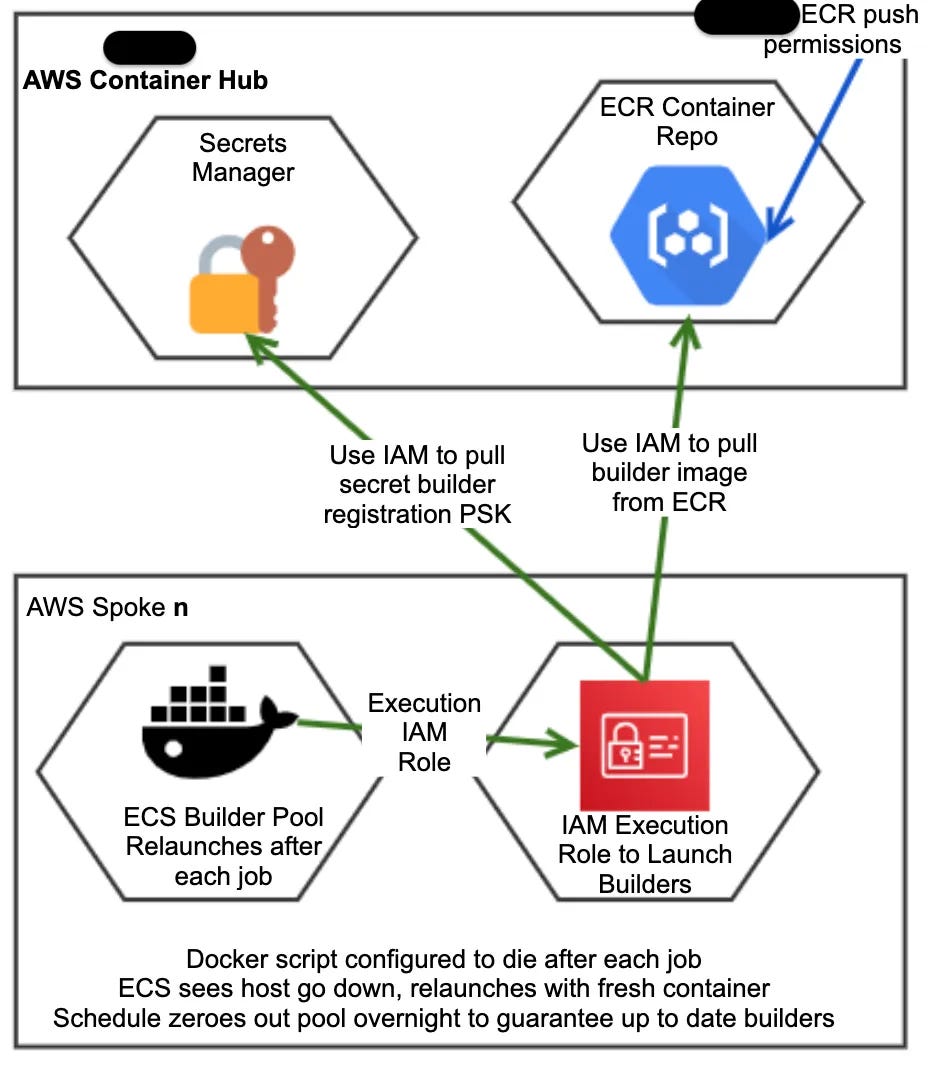
This blog focuses on our builders — as we’ve scaled out our AWS accounts, we’ve been registering a single small Amazon Linux host to be a runner in each account. That is a boon to authentication security — it can use an assumed IAM role within the account to manage it, rather than authenticating with a static IAM user, but a pain for management and inter-pipeline security. Let’s talk about each separately.
First, management. These are long-lived ec2 hosts that need to be monitored, rebooted occasionally, and patched. That overhead is an anti-pattern for the containerized, serverless models of modern applications. So it’s gotta go.
Second, inter-pipeline security. Pipelines in CI/CDs often have access to privileged information — they connect to secrets stores like SSM or Vault, sometimes copying those secrets to the local disk when doing compute or ETL operations. Now image those artifacts aren’t cleaned up, and a second malicious pipeline runs on the same builder and uploads every file it can get access to to somewhere else. That’s not great. There are mitigations you can build in, like each pipeline cleaning its artifacts, or making sure all teams running jobs don’t store secrets on disk, but that’s very much a herding-cats model. It’s gotta go.
New Model Goals
I spent a lot of time mapping out a new model with another architect, Sai Gunaranjan, and figuring out what our goals are. Here’s what we need to satisfy:
Container or serverless driven, no servers! Containers have myriad benefits, including easy relaunch on issues, and can be frequently rebuilt to include security patches
Runners should run a single job only, and then die, so no risk of leaking secrets between jobs
Centralized repository and secret access, so there isn’t a continued need to update secrets and docker image in many locations
Easy to deploy, with a robust, standardized Terraform module
New Model: Centralized ECR and Secrets, ECS Runners
We have to solve this in both the Azure and AWS space for business reasons. I know the AWS side better, so I own that. I elected to create a “Hub” account that stores all the non-duplicated items (ECR, secret), and have many “spoke” accounts that will store their own ECS service, task definition, and scheduling.
In the single “Hub” account, I created several resources:
An ECR to store the builder container image that spoke accounts will pull, and created an ECR policy to permit inter-account access
A secrets manager “secret” that I populated with the “PAT” token (used to authenticate to Azure DevOps (ADO) and register as a builder and a secret policy permitting inter-account access
A KMS CMK, a customer-created and managed encryption key, which is used to encrypt the secret, and also a KMS policy which permits “spoke” accounts to access this CMK so they can decrypt the secrets manager secret
In each runner “Spoke” account we call a terraform module that creates:
Cloudwatch log group — Most AWS services optionally use logs, and need somewhere to store them
An IAM “execution” role (and policies) used to pull the ECR image and access secrets
An ECS Fargate cluster — Contains almost no config, but defines underlying hardware type, here “FARGATE”
An ECS task definition that defines how large the runner and underlying Fargate host should be, as well as container location and environment (and secret) information
An ECS service to run
nnumber of the above ECS task and handle replacing it after it diesAn autoscaling target to link autoscaling policies with the ECS service
Autoscaling schedules to spin up more runners during business hours when they are most active, and fewer after-hours, and also 0 out the runner pool each night to trigger mandatory container redeployments each morning — I’ll talk about the logic here more later in this blog
AWS Cross-Account IAM Access
AWS has a much-maligned, and very finicky security model. It’s incredibly powerful, but also so complex it’s sometimes painful to work with.
The model basically works from both sides of access:
A target resource that is
receivinga request must have an IAM policy permitting it to receive that request from the sending resourceA resource
sendingthe request must have a policy that permits it to send the request to the target
Keep that in mind as I show the specific config below, and we’ll talk about both sides.
There’s also an interesting catch-22 here — whenever you update an IAM policy, it checks to make sure the “principal” (resource) exists. This means that you can’t proactively create the hub policy before creating the spoke IAM resources, because the hub IAM policies will say the spoke IAM roles don’t exist, so the principal is invalid. This means we need to follow an interesting deployment strategy:
First, deploy the Hub resources without policies. These need to exist so spoke IAM can be created
Second, deploy the IAM execution roles in each Spoke account, with policies to permit access to the Hub resources
Third, deploy policies in the Hub account to permit spoke access
Fourth, deploy the ECS service and task in the Spoke accounts, which should now spin up and succeed
This is a huge bummer in terms of parallel deployment — if your account management is account-based, like ours is, you’ll have issues. If you’re managing your multiple accounts with Terraform workspaces (or CloudFormation?), you could stage the deployment, and manually do each of the four steps in the proper order.
I’ll walk through the resources and policies together, but keep in mind the deployment steps above for when you build it yourself.
Azure DevOps Builder Image
I’ll write another blog for how we designed, built, and tested the docker image. For now, assume the docker image works well, and accepts the following 3 environmental variables to configure itself:
AZP_URL — The location of your Azure DevOps Org, e.g.
https://dev.azure.com/foobarAZP_POOL — The name of the existing pool on Azure DevOps to register into. NOTE: Make sure this pool exists before attempting to programmatically register to it — hosts can’t create a pool when they register.
AZP_TOKEN — a secret token permitting hosts to register to builder pools. This token is created under a specific administrator user (or service principal) and expires periodically. More info here.
Hub Account Resources
ECR and Policy
First, we need somewhere to store our docker image file. AWS permits only a single image to be stored in a single ECR — I like this model, compared with Azure’s “many images in a single ACR.” ECRs have a name, and not much else. I recommend enabling “scan_on_push” to get AWS’s built-in image security scanning and reporting.
Mutability is a topic of much discussion among the docker community. Flexibility-heavy orgs leave MUTABLE on, and this permits over-writing tags with a new version that should be used. Structured, or security-heavy orgs, turn off mutability and often use image tags to track versions, and once an image tag is registered it can’t be over-written. Totally up to you and your org!
| resource "aws_ecr_repository" "hub_ecr_repository" { | |
| name = "hub_ecr_repository" | |
| image_tag_mutability = "MUTABLE" | |
| image_scanning_configuration { | |
| scan_on_push = true | |
| } | |
| tags = { | |
| name = "hub_ecr_repository" | |
| terraform = "true" | |
| } | |
| } |
We also need an ECR policy that permits the spoke accounts to get to this image. You can either grant access to arn:aws:iam::1234567890:root which grants access to any resource in an account to get to it, or you can grant access to something like arn:aws:iam::1234567890:role/FooBarRole, which grants access only to that specific IAM role. The image source I don’t think is very sensitive, so I use the :root method here, but the secret and CMK policy next are very sensitive, so we are more specific there.
| resource "aws_ecr_repository_policy" "hub_ecr_repository_policy" { | |
| repository = aws_ecr_repository.hub_ecr_repository.name | |
| policy = jsonencode( | |
| { | |
| "Version" : "2008-10-17", | |
| "Statement" : [ | |
| { | |
| "Sid" : "AllowSpokeAccountsToPull", | |
| "Effect" : "Allow", | |
| "Principal" : { | |
| "AWS" : [ | |
| "arn:aws:iam::1234567890:root" | |
| ] | |
| }, | |
| "Action" : [ | |
| "ecr:GetDownloadUrlForLayer", | |
| "ecr:BatchGetImage", | |
| "ecr:BatchCheckLayerAvailability" | |
| ] | |
| } | |
| ] | |
| } | |
| ) | |
| } |
KMS CMK and Policy
Next we want to create a secret and permit sharing it between accounts. However, secrets are encrypted with a key so not even AWS can decrypt them. This is a great security model, but means we need to share the encryption key between accounts first before we share the secret, or the spoke accounts will get to the secret but not be able to decrypt it. So first let’s talk KMS CMK.
KMS keys are created as a distinct resource, and their policies permit not even granting the hosting account access to the key, which isn’t ideal. So first we grant access to arn:aws:iam::aaaaaaaa:root, where aaaaaa is the account ID of the Hub account. This permits the console and APIs to manage the key, something we expect and want.
The second stanza permits a specific IAM role in a spoke account to get to this resource. Remember, the IAM role must already exist in the spoke account, or this policy will be rejected by the AWS API.
| resource "aws_kms_key" "hub_secrets_manager_cmk" { | |
| description = "KMS CMK for Secrets Manager" | |
| policy = jsonencode( | |
| { | |
| "Version" : "2012-10-17", | |
| "Id" : "auto-secretsmanager-2", | |
| "Statement" : [ | |
| { | |
| "Sid" : "Enable IAM User Permissions", | |
| "Effect" : "Allow", | |
| "Principal" : { | |
| "AWS" : "arn:aws:iam::aaaaaaaaaaa:root" #Root account ARN (remember to remove these comments before deploying, json doesn't like comments) | |
| }, | |
| "Action" : "kms:*", | |
| "Resource" : "*" | |
| }, | |
| { | |
| "Sid" : "SpokeBuilderAccess", | |
| "Effect" : "Allow", | |
| "Action" : [ | |
| "kms:Decrypt", | |
| "kms:DescribeKey" | |
| ], | |
| "Resource" : "*", | |
| "Principal" : { | |
| "AWS" : [ | |
| "arn:aws:iam::bbbbbbbbbb:role/SpokeABuilderExecutionRole" | |
| ] | |
| } | |
| } | |
| ] | |
| } | |
| ) | |
| tags = { | |
| Terraform = "true" | |
| } | |
| } |
Next, we create a KMS alias. This isn’t strictly required, but it’s helpful for the humans to keep track of keys and give them aliases (read: names).
| resource "aws_kms_alias" "hub_secrets_manager_cmk_alias" { | |
| name = "alias/hub_secrets_manager_cmk" | |
| target_key_id = aws_kms_key.hub_secrets_manager_cmk.key_id | |
| } |
Secrets Manager Secret — PAK
Now that the KMS key is shared with the spoke account, they can decrypt stuff that is encrypted with it, like the Hub’s secret! Let’s create that secret. Note that need to call out the KMS key used to encrypt this secret, or it’ll be encrypted with a different KMS key that hasn’t been shared.
Also note that the actual PAK secret isn’t provided or in terraform at all. Once this secret is created, you’d login to the AWS console by hand and populate this secret.
| resource "aws_secretsmanager_secret" "hub_ado_join_pak" { | |
| name = "AzureDevOps_JoinBuildPool_PAK" | |
| kms_key_id = aws_kms_key.hub_secrets_manager_cmk.arn | |
| tags = { | |
| Terraform = "true" | |
| } | |
| } |
Open the AWS console, and find the secret there. Scroll down to “retrieve secret value” and click it. It’ll show default values.

Click on edit in the top right.
Update the default value to the PAK you’d like your builders to use and hit save. Make sure to use the “Plaintext” type of secret, rather than json-based key/value type.

Now that our key is created and populated, we need to attach a secret policy to permit multi-account access. We use the same IAM spoke role as above.
| resource "aws_secretsmanager_secret_policy" "hub_ado_join_pak" { | |
| secret_arn = aws_secretsmanager_secret.hub_ado_join_pak.arn | |
| policy = jsonencode( | |
| { | |
| "Version" : "2012-10-17", | |
| "Statement" : [{ | |
| "Sid" : "AzureDevOpsBuildersSecretsAccess", | |
| "Effect" : "Allow", | |
| "Action" : "secretsmanager:GetSecretValue", | |
| "Resource" : "*", | |
| "Principal" : { | |
| "AWS" : [ | |
| "arn:aws:iam::bbbbbbbbbb:role/SpokeABuilderExecutionRole" | |
| ] | |
| } | |
| }] | |
| }) | |
| } |
And that’s it for the Hub account — now we can work on Spoke accounts, which is where the cool stuff lives anyway. Let’s walk through the resources required there.
Spoke Account Resources
All the items above we’ll build in only one account, the Hub. All of the following resources we’ll build in every single “runner” or “Spoke” account. These spoke accounts will draw on the ECR, secret, and KMS CMK from the Hub account.
Cloudwatch Log Group
Every AWS resource supports extensive logging, but it often is disabled by default. For ECS services and tasks to log, we need to create a cloudwatch log group to receive the logs. No policies here — most access is within the spoke account, which will work by default.
| resource "aws_cloudwatch_log_group" "AzureDevOpsBuilderLogGroup" { | |
| name = "AzureDevOpsBuilderLogGroup" | |
| tags = { | |
| Terraform = "true" | |
| Name = "AzureDevOpsBuilderLogGroup" | |
| } | |
| } |
ECS Task Execution Role and Policies
An ECS task ties together all sorts of stuff — a container definition, IAM roles to use to access required resources, sizing, and logging. The first one we’ll build is the “Execution IAM Role” — this is used when the ECS task is launched and needs to have the ability to access all required resources.
This is also the IAM role that you’ll need to permit access in the Hub account above, since it’s the resource that’ll be doing the requesting.
| resource "aws_iam_role" "SpokeABuilderExecutionRole" { | |
| name = "SpokeABuilderExecutionRole" | |
| assume_role_policy = jsonencode({ | |
| Version = "2012-10-17" | |
| Statement = [ | |
| { | |
| Action = "sts:AssumeRole" | |
| Effect = "Allow" | |
| Sid = "" | |
| Principal = { | |
| Service = "ecs-tasks.amazonaws.com" | |
| } | |
| }, | |
| ] | |
| }) | |
| tags = { | |
| Name = "SpokeABuilderExecutionRole" | |
| Terraform = "true" | |
| } | |
| } |
To permit most ECS tasks, like launching the ECS, writing logs, etc., AWS provides an IAM role that we can use and attach to. So let’s do that:
| resource "aws_iam_role_policy_attachment" "SpokeABuilderExecutionRole_to_ecsTaskExecutionRole" { | |
| role = aws_iam_role.SpokeABuilderExecutionRole.name | |
| policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy" | |
| } |
We also want to permit this requesting IAM role to get to the Hub’s secret and the KMS CMK key it is encrypted with.
Note that we don’t need to grant access to the Hub’s ECR since the above AmazonECSTaskExecutionRolePolicy already grants it.
| resource "aws_iam_role_policy" "SpokeABuilderExecutionRoleSsmRead" { | |
| name = "SpokeABuilderExecutionRoleSsmRead" | |
| role = aws_iam_role.SpokeABuilderExecutionRole.id | |
| policy = jsonencode( | |
| { | |
| "Version" : "2012-10-17", | |
| "Statement" : [ | |
| { | |
| "Effect" : "Allow", | |
| "Action" : [ | |
| "secretsmanager:GetSecretValue" | |
| ], | |
| "Resource" : [ | |
| "arn:aws:secretsmanager:us-east-1:aaaaaaaaaaa:secret:SecretName*" <-- Note the "*" at the end, this is required, the ARN in the Hub account | |
| ] | |
| }, | |
| { | |
| "Effect" : "Allow", | |
| "Action" : [ | |
| "kms:Decrypt" | |
| ], | |
| "Resource" : [ | |
| "arn:aws:kms:us-east-1:aaaaaaaa:key/1111111-22222-33333-444444444444" <-- The ARN of the key in the Hub account | |
| ] | |
| } | |
| ] | |
| } | |
| ) | |
| } |
ECS Cluster
The ECS cluster doesn’t do much — it defines who will provide the compute for any tasks or services assigned to it, and we say we’d prefer FARGATE, where AWS provides the compute for us.
| resource "aws_ecs_cluster" "fargate_cluster" { | |
| name = "AzureDevOpsBuilderCluster" | |
| capacity_providers = [ | |
| "FARGATE" | |
| ] | |
| default_capacity_provider_strategy { | |
| capacity_provider = "FARGATE" | |
| } | |
| } |
ECS Task Definition
The ECS task definition has a LOT of jobs! I added notes in the config below to help guide you — we define an in-VPC task that pulls the Hub’s ECR docker image (with an optional tag), and also grabs the secret from the Hub and injects it, as well as a few other non-secret environmental variables.
There’s more than I can cover quickly, please read over the below.
| resource "aws_ecs_task_definition" "azure_devops_builder_task" { | |
| family = "AzureDevOpsBuilder" | |
| execution_role_arn = aws_iam_role.SpokeABuilderExecutionRole.arn | |
| #task_role_arn = xxxxxx # Optional, ARN of IAM role assigned to container once booting, grants rights | |
| network_mode = "awsvpc" | |
| requires_compatibilities = ["FARGATE"] | |
| # Fargate cpu/mem must match available options: https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task-cpu-memory-error.html | |
| cpu = var.fargate_cpu # Variable, default to 1024 | |
| memory = var.fargate_mem # Variable, defaults to 2048 | |
| container_definitions = jsonencode( | |
| [ | |
| { | |
| name = "AzureDevOpsBuilder" | |
| image = "${var.image_ecr_url}:${var.image_tag}" # The URL of the Hub's ECR and a tag, e.g. aaaaaaa.dkr.ecr.us-east-1.amazonaws.com/hub_ecr_repository:prod | |
| cpu = "${var.container_cpu}" # Variable, default to 1024 | |
| memory = "${var.container_mem}" # Variable, defaults to 2048 | |
| essential = true | |
| environment : [ | |
| { name : "AZP_URL", value : "https://dev.azure.com/foobar" }, | |
| { name : "AZP_POOL", value : "BuilderPoolName" } # Optional, builder will join "default" pool if not provided | |
| ] | |
| secrets : [ | |
| { name : "AZP_TOKEN", valueFrom : "${var.ado_join_secret_token_arn}" } # ARN of Hub's secret to fetch and inject | |
| ] | |
| logConfiguration : { | |
| logDriver : "awslogs", | |
| options : { | |
| awslogs-group : "AzureDevOpsBuilderLogGroup", | |
| awslogs-region : "${data.aws_region.current_region.name}", # Data source to gather region, e.g. data "aws_region" "current_region" {} | |
| awslogs-stream-prefix : "AzureDevOpsBuilder" | |
| } | |
| } | |
| } | |
| ] | |
| ) | |
| tags = { | |
| Name = "AzureDevOpsBuilder" | |
| } | |
| } |
ECS Service
The ECS service is a host for a task, and defines the subnets and security groups to assign to any tasks spun up within it. We also make sure to ignore the “desired_count” variable so we can use scheduled tasks to update that value on a cron schedule.
| resource "aws_ecs_service" "azure_devops_builder_service" { | |
| name = "AzureDevOpsBuilderService" | |
| cluster = aws_ecs_cluster.fargate_cluster.id | |
| task_definition = aws_ecs_task_definition.azure_devops_builder_task.arn | |
| desired_count = var.autoscale_task_weekday_scale_down # Defaults to 1 instance of the task | |
| launch_type = "FARGATE" | |
| platform_version = "LATEST" | |
| network_configuration { | |
| subnets = var.service_subnets # List of subnets for where service should launch tasks in | |
| security_groups = var.service_sg # List of security groups to provide to tasks launched within service | |
| } | |
| lifecycle { | |
| ignore_changes = [desired_count] # Ignored desired count changes live, permitting schedulers to update this value without terraform reverting | |
| } | |
| } |
App AutoScale Target
We want to do scaling of this service based on a cron schedule, which means we’ll need to create an “aws_appautoscaling_target” which is able to connect scheduling mechanisms scheduled tasks. We set min and max capacity, but also ignore them since the values here will be over-ridden by scheduled tasks.
| resource "aws_appautoscaling_target" "AzureDevOpsBuilderServiceAutoScalingTarget" { | |
| count = var.enable_scaling ? 1 : 0 | |
| min_capacity = var.autoscale_task_weekday_scale_down | |
| max_capacity = var.autoscale_task_weekday_scale_up | |
| resource_id = "service/${aws_ecs_cluster.fargate_cluster.name}/${aws_ecs_service.azure_devops_builder_service.name}" # service/(clusterName)/(serviceName) | |
| scalable_dimension = "ecs:service:DesiredCount" | |
| service_namespace = "ecs" | |
| lifecycle { | |
| ignore_changes = [ | |
| min_capacity, | |
| max_capacity, | |
| ] | |
| } | |
| } |
ECS AutoScaling Schedule
Now we’re able to define particular schedules using cron, and figure out a schedule. There’s two major things we’re doing with these schedules:
Scale down at end of day to save $$, and scale up at beginning of workday to provide adequate compute for jobs
Scale to 0 at midnight of each day to make sure any host is alive for a max of 24 hours before being replaced
Note the timezone modifier for cron — unlike most services, we don’t need to create definitions in UTC.
| # Scale up weekdays at beginning of day | |
| resource "aws_appautoscaling_scheduled_action" "ADOBuilderWeekdayScaleUp" { | |
| count = var.enable_scaling ? 1 : 0 | |
| name = "ADOBuilderScaleUp" | |
| service_namespace = aws_appautoscaling_target.AzureDevOpsBuilderServiceAutoScalingTarget[0].service_namespace | |
| resource_id = aws_appautoscaling_target.AzureDevOpsBuilderServiceAutoScalingTarget[0].resource_id | |
| scalable_dimension = aws_appautoscaling_target.AzureDevOpsBuilderServiceAutoScalingTarget[0].scalable_dimension | |
| schedule = "cron(0 6 ? * MON-FRI *)" #Every weekday at 6 a.m. | |
| timezone = "America/Los_Angeles" | |
| scalable_target_action { | |
| min_capacity = var.autoscale_task_weekday_scale_up | |
| max_capacity = var.autoscale_task_weekday_scale_up | |
| } | |
| } | |
| # Scale down weekdays at end of day | |
| resource "aws_appautoscaling_scheduled_action" "ADOBuilderWeekdayScaleDown" { | |
| count = var.enable_scaling ? 1 : 0 | |
| name = "ADOBuilderScaleDown" | |
| service_namespace = aws_appautoscaling_target.AzureDevOpsBuilderServiceAutoScalingTarget[0].service_namespace | |
| resource_id = aws_appautoscaling_target.AzureDevOpsBuilderServiceAutoScalingTarget[0].resource_id | |
| scalable_dimension = aws_appautoscaling_target.AzureDevOpsBuilderServiceAutoScalingTarget[0].scalable_dimension | |
| schedule = "cron(0 20 ? * MON-FRI *)" #Every weekday at 8 p.m. | |
| timezone = "America/Los_Angeles" | |
| scalable_target_action { | |
| min_capacity = var.autoscale_task_weekday_scale_down | |
| max_capacity = var.autoscale_task_weekday_scale_down | |
| } | |
| } | |
| # Scale to 0 to refresh fleet | |
| resource "aws_appautoscaling_scheduled_action" "ADOBuilderRefresh" { | |
| count = var.enable_scaling ? 1 : 0 | |
| name = "ADOBuilderRefresh" | |
| service_namespace = aws_appautoscaling_target.AzureDevOpsBuilderServiceAutoScalingTarget[0].service_namespace | |
| resource_id = aws_appautoscaling_target.AzureDevOpsBuilderServiceAutoScalingTarget[0].resource_id | |
| scalable_dimension = aws_appautoscaling_target.AzureDevOpsBuilderServiceAutoScalingTarget[0].scalable_dimension | |
| schedule = "cron(0 0 ? * MON-FRI *)" #Every weekday at midnight | |
| timezone = "America/Los_Angeles" | |
| scalable_target_action { | |
| min_capacity = 0 | |
| max_capacity = 0 | |
| } | |
| } |
Profit!
Phew, that’s a lot of resources and configuration, isn’t it! Now that this is in place, you should have n Spoke accounts running their own builders, and each automatically polling your Hub account for new images at least once a day, and if the image is set to die after one run (which we do, and recommend!), then it’ll grab it after running each job.
The full codebase is here:
KyMidd/Terraform_ADO_ECR_Multi-Account_Access
Assume "aaaaaaa" account is the Hub where secret and ECR lives, and "bbbbbb" account is a single spoke account. Spoke…github.com
Please have fun building this yourself, and good luck out there!
kyler