


🔥Building a Slack Bot with AI Capabilities - Part 8, ReRanking Bedrock Knowledge Base Vectors to Improve Result Relevancy🔥
aka, just give me those GOOD vectors please

This blog series focuses on presenting complex DevOps projects as simple and approachable via plain language and lots of pictures. You can do it!
This article is part of a series of articles, because 1 article would be absolutely massive.
Part 1: Covers how to build a slack bot in websocket mode and connect to it with python
Part 4: How to convert your local script to an event-driven serverless, cloud-based app in AWS Lambda
Part 7: Streaming token responses from AWS Bedrock to your AI Slack bot using converse_stream()
Part 8 (this article!): ReRanking knowledge base responses to improve AI model response efficacy
Part 9: Adding a Lambda Receiver tier to reduce cost and improve Slack response time
Hey all!
So far in this series we’ve created a slack app, connected that to a tiered python-based lambda system, and built all the logic to relay all that sweet sweet slack context over to the bedrock AI.
It’s all serverless, we’re using a RAG knowledge base against Confluence to make sure our bot has memorized all our internal enterprise information , and we’re even streaming tokens from bedrock to start responding right away (and be as cool as platforms like ChatGPT).
We’re even using converse(), AWS’s front-end API to help map our conversation to each model’s requested API format, so we can easily swap out the AI to different models.
In this article, we’re going to talk about ReRanking. ReRanking is an understated technology. It reads your input question/conversation, and all your knowledge base results, and gives you a list of the best ones, with their relevancy score added as metadata. It takes only a quarter of a second to run on 50 results, the max I’ve scaled it.
And it improves the accuracy and relevancy of your bot’s answers DRAMATICALLY
Seriously, it’s so much better.
I have a mentor at work, who used this analogy:
Your knowledge base using Retrieve() is like a librarian scooping up books off a shelf that are near to your keywords. Are those books related to your question? No idea, but they look similar!
A ReRanker reads all the books the librarian picked out and then just gives you the number of requests that are most related, and tells you which ones to read first.
Empowering your model with weighted responses, and skipping the text vectors that are least likely an answer to the question your users are asking, is INCREDIBLY IMPACTFUL.
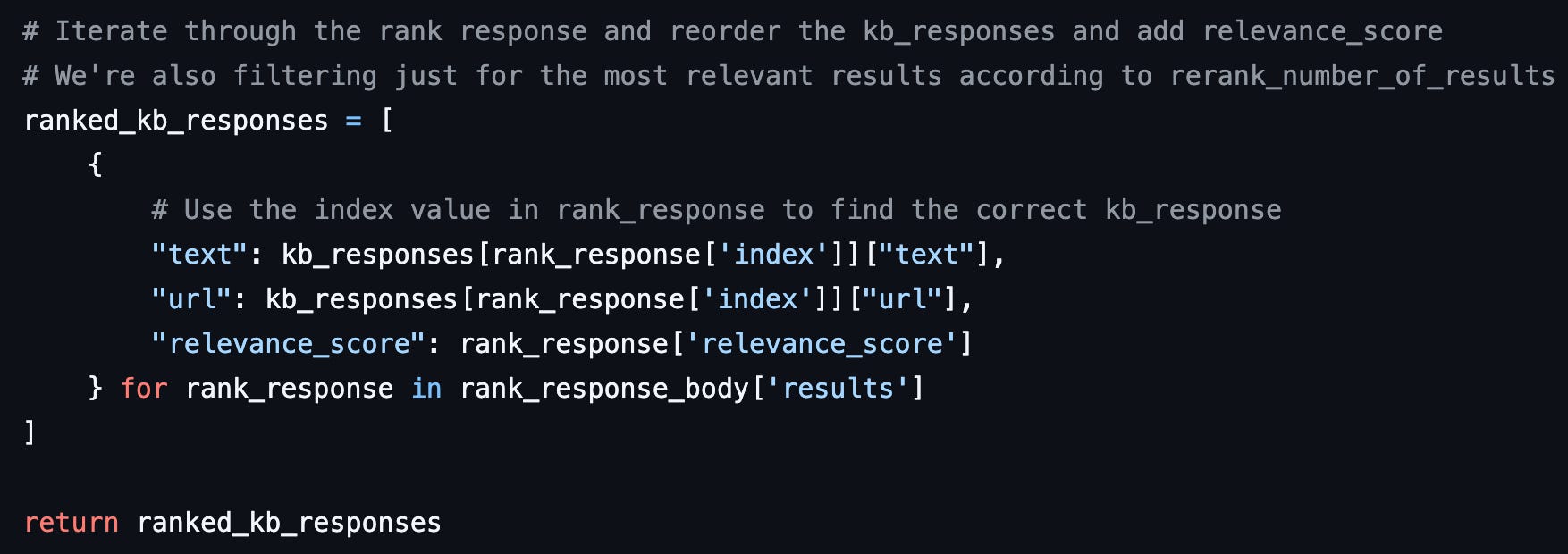
You get it. You’ve read this far, and you’re ready to improve the fidelity of your knowledge base results. All for the low low cost of almost no time, and almost no money. Lets do this.
Getting the ReRanker
Keep reading with a 7-day free trial
Subscribe to Let's Do DevOps to keep reading this post and get 7 days of free access to the full post archives.